mirror of https://github.com/koide3/small_gicp.git
4.1 KiB
4.1 KiB
Benchmark
Build
cd small_gicp
mkdir build && cd build
cmake .. -DBUILD_WITH_TBB=ON -DBUILD_WITH_PCL=ON -DBUILD_BENCHMARKS=ON
# [optional] Build with Iridescence (visualization)
git clone https://github.com/koide3/iridescence --recursive
mkdir iridescence/build && cd iridescence/build
cmake .. && make -j
sudo make install
cmake .. -DBUILD_WITH_IRIDESCENCE=ON
# [optional] Build with fast_gicp
export FAST_GICP_INCLUDE_DIR=/your/fast_gicp/include
cmake .. -DBUILD_WITH_FAST_GICP=ON
# Build
make -j
# Test
# Show options
./odometry_benchmark
# USAGE: odometry_benchmark <dataset_path> <output_path> [options]
# OPTIONS:
# --visualize
# --num_threads <value> (default: 4)
# --num_neighbors <value> (default: 20)
# --downsampling_resolution <value> (default: 0.25)
# --voxel_resolution <value> (default: 2.0)
# --engine <pcl|small_gicp|small_gicp_omp|small_vgicp_omp|small_gicp_tbb|small_vgicp_tbb|small_vgicp_model_tbb|small_gicp_tbb_flow> (default: small_gicp)
# Run odometry benchmark
./odometry_benchmark /your/kitti/dataset/velodyne /tmp/traj_lidar.txt --visualize --num_threads 16 --engine small_gicp_tbb
Results
All benchmarks were conducted on the KITTI 00 sequence.
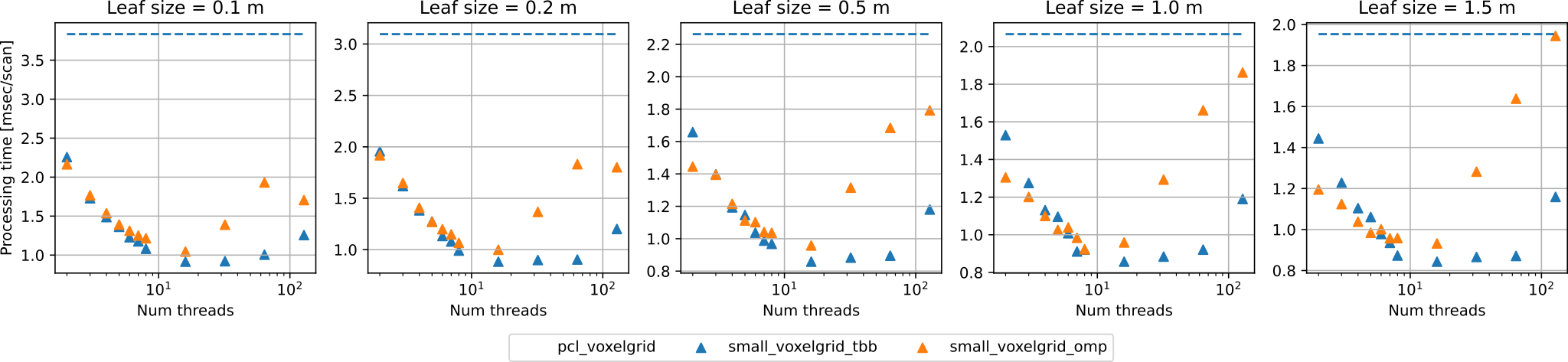
Downsampling
cd small_gicp/scripts
./run_downsampling_benchmark.sh
python3 plot_downsampling.py
- Single-threaded
small_gicp::voxelgrid_samplingis about 1.3x faster thanpcl::VoxelGrid. - Multi-threaded
small_gicp::voxelgrid_sampling_tbb(6 threads) is about 3.2x faster thanpcl::VoxelGrid. small_gicp::voxelgrid_samplinggives accurate downsampling results (almost identical to those ofpcl::VoxelGrid) whilepcl::ApproximateVoxelGridyields spurious points (up to 2x points).small_gicp::voxelgrid_samplingcan process a larger point cloud with a fine voxel resolution compared topcl::VoxelGrid(for a point cloud of 1000m width, minimum voxel resolution can be 0.5 mm).

- While TBB shows slightly better scalability, both the parallelism backends do not obtain a speed gain for the cases with threads more than 16.
KdTree construction
cd small_gicp/scripts
./run_kdtree_benchmark.sh
python3 plot_kdtree.py
- Multi-threaded implementation (TBB and OMP) can be up to 4x faster than the single-threaded one (All the implementations are based on nanoflann).
- The processing speed gets faster as the number of threads increases, but the speed gain is not monotonic sometimes (because of the scheduling algorithm or some CPU(AMD 5995WX)-specific issues?).
- This benchmark only compares the construction time (query time is not included).

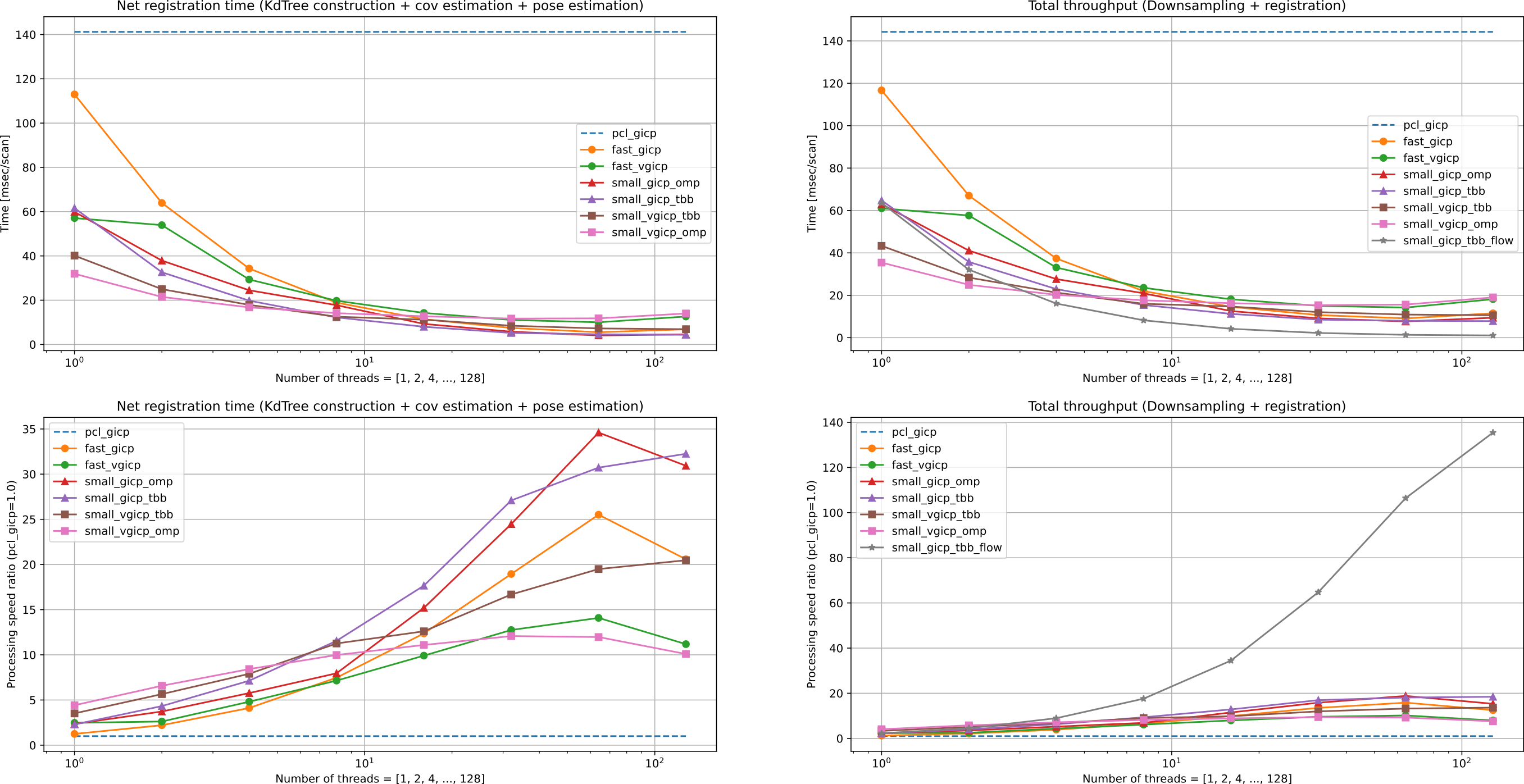
Odometry estimation
cd small_gicp/scripts
./run_odometry_benchmark.sh
python3 plot_odometry.py
- Single-thread
small_gicp::GICPis about 2.4x and 1.9x faster thanpcl::GICPandfast_gicp::GICP, respectively. small_gicp::(GICP|VGICP)shows a better multi-thread scalability compared tofast_gicp::(GICP|VGICP).small_gicp::GICPparallelized with TBB flow graph shows an excellent scalability to many-threads situations (~128 threads) but with latency degradation.
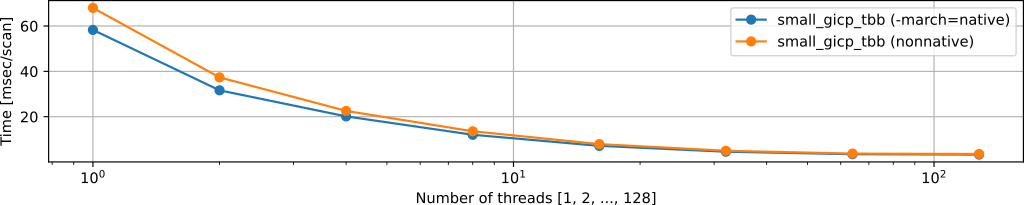
SIMD intrinsics (-march=native) (We recommend keeping this feature disabled unless you are 100% sure what it is)
BUILD_WITH_MARCH_NATIVE=ONenables platform-specific intrinsics and squeezing the performance (1.1x speedup for free).- However, you must ensure that all involved libraries are built with
-march=native, otherwise the program will crash. - Generally, it is difficult to properly set
-march=nativefor all libraries, and we recommend keepingBUILD_WITH_MARCH_NATIVE=OFF.
Results:
BUILD_WITH_MARCH_NATIVE=OFF:Eigen::SimdInstructionSetsInUse()=SSE, SSE2BUILD_WITH_MARCH_NATIVE=ON:Eigen::SimdInstructionSetsInUse()=AVX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2