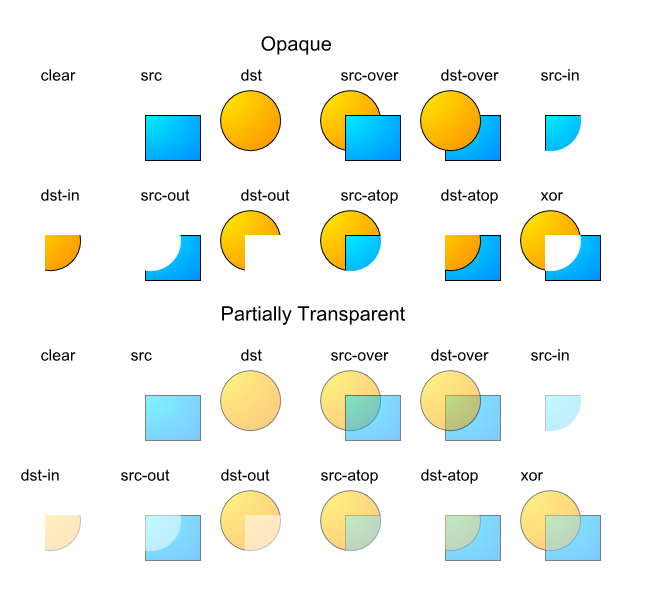{kind=link}
 -
--Cgo lets Go packages call C code. Given a Go source file written with some -special features, cgo outputs Go and C files that can be combined into a -single Go package. -
- -
-To lead with an example, here's a Go package that provides two functions -
-Random and Seed - that wrap C's rand
-and srand functions.
-
-Let's look at what's happening here, starting with the import statement. -
- -
-The rand package imports "C", but you'll find there's
-no such package in the standard Go library. That's because C is a
-"pseudo-package", a special name interpreted by cgo as a reference to C's
-name space.
-
-The rand package contains four references to the C
-package: the calls to C.rand and C.srand, the
-conversion C.uint(i), and the import statement.
-
-The Random function calls the standard C library's random
-function and returns the result. In C, rand returns a value of the
-C type int, which cgo represents as the type C.int.
-It must be converted to a Go type before it can be used by Go code outside this
-package, using an ordinary Go type conversion:
-
-Here's an equivalent function that uses a temporary variable to illustrate -the type conversion more explicitly: -
- -{{code "/doc/progs/cgo2.go" `/func Random/` `/STOP/`}} - -
-The Seed function does the reverse, in a way. It takes a
-regular Go int, converts it to the C unsigned int
-type, and passes it to the C function srand.
-
-Note that cgo knows the unsigned int type as C.uint;
-see the cgo documentation for a complete list of
-these numeric type names.
-
-The one detail of this example we haven't examined yet is the comment
-above the import statement.
-
-Cgo recognizes this comment. Any lines starting
-with #cgo
-followed
-by a space character are removed; these become directives for cgo.
-The remaining lines are used as a header when compiling the C parts of
-the package. In this case those lines are just a
-single #include
-statement, but they can be almost any C code. The #cgo
-directives are
-used to provide flags for the compiler and linker when building the C
-parts of the package.
-
-There is a limitation: if your program uses any //export
-directives, then the C code in the comment may only include declarations
-(extern int f();), not definitions (int f() {
-return 1; }). You can use //export directives to
-make Go functions accessible to C code.
-
-The #cgo and //export directives are
-documented in
-the cgo documentation.
-
-Strings and things -
- --Unlike Go, C doesn't have an explicit string type. Strings in C are -represented by a zero-terminated array of chars. -
- -
-Conversion between Go and C strings is done with the
-C.CString, C.GoString, and
-C.GoStringN functions. These conversions make a copy of the
-string data.
-
-This next example implements a Print function that writes a
-string to standard output using C's fputs function from the
-stdio library:
-
-Memory allocations made by C code are not known to Go's memory manager.
-When you create a C string with C.CString (or any C memory
-allocation) you must remember to free the memory when you're done with it
-by calling C.free.
-
-The call to C.CString returns a pointer to the start of the
-char array, so before the function exits we convert it to an
-unsafe.Pointer and release
-the memory allocation with C.free. A common idiom in cgo programs
-is to defer
-the free immediately after allocating (especially when the code that follows
-is more complex than a single function call), as in this rewrite of
-Print:
-
-Building cgo packages -
- -
-To build cgo packages, just use "
-go build" or
-"go install
-" as usual. The go tool recognizes the special "C" import and automatically
-uses cgo for those files.
-
-More cgo resources -
- --The cgo command documentation has more detail about -the C pseudo-package and the build process. The cgo examples -in the Go tree demonstrate more advanced concepts. -
- --For a simple, idiomatic example of a cgo-based package, see Russ Cox's gosqlite. -Also, the Go Community Wiki -lists many packages, some of which use cgo. -
- --Finally, if you're curious as to how all this works internally, take a look -at the introductory comment of the runtime package's cgocall.c. -
diff --git a/doc/articles/concurrency_patterns.html b/doc/articles/concurrency_patterns.html deleted file mode 100644 index 62168b840b..0000000000 --- a/doc/articles/concurrency_patterns.html +++ /dev/null @@ -1,79 +0,0 @@ - - -
-Concurrent programming has its own idioms. A good example is timeouts. Although
-Go's channels do not support them directly, they are easy to implement. Say we
-want to receive from the channel ch, but want to wait at most one
-second for the value to arrive. We would start by creating a signalling channel
-and launching a goroutine that sleeps before sending on the channel:
-
-We can then use a select statement to receive from either
-ch or timeout. If nothing arrives on ch
-after one second, the timeout case is selected and the attempt to read from
-ch is abandoned.
-
-The timeout channel is buffered with space for 1 value, allowing
-the timeout goroutine to send to the channel and then exit. The goroutine
-doesn't know (or care) whether the value is received. This means the goroutine
-won't hang around forever if the ch receive happens before the
-timeout is reached. The timeout channel will eventually be
-deallocated by the garbage collector.
-
-(In this example we used time.Sleep to demonstrate the mechanics
-of goroutines and channels. In real programs you should use
-time.After, a function that returns
-a channel and sends on that channel after the specified duration.)
-
-Let's look at another variation of this pattern. In this example we have a -program that reads from multiple replicated databases simultaneously. The -program needs only one of the answers, and it should accept the answer that -arrives first. -
- -
-The function Query takes a slice of database connections and a
-query string. It queries each of the databases in parallel and
-returns the first response it receives:
-
-In this example, the closure does a non-blocking send, which it achieves by
-using the send operation in select statement with a
-default case. If the send cannot go through immediately the
-default case will be selected. Making the send non-blocking guarantees that
-none of the goroutines launched in the loop will hang around. However, if the
-result arrives before the main function has made it to the receive, the send
-could fail since no one is ready.
-
-This problem is a textbook example of what is known as a
-race condition, but
-the fix is trivial. We just make sure to buffer the channel ch (by
-adding the buffer length as the second argument to make),
-guaranteeing that the first send has a place to put the value. This ensures the
-send will always succeed, and the first value to arrive will be retrieved
-regardless of the order of execution.
-
-These two examples demonstrate the simplicity with which Go can express complex -interactions between goroutines. -
diff --git a/doc/articles/defer_panic_recover.html b/doc/articles/defer_panic_recover.html deleted file mode 100644 index c964cd368c..0000000000 --- a/doc/articles/defer_panic_recover.html +++ /dev/null @@ -1,197 +0,0 @@ - - --Go has the usual mechanisms for control flow: if, for, switch, goto. It also -has the go statement to run code in a separate goroutine. Here I'd like to -discuss some of the less common ones: defer, panic, and recover. -
- --A defer statement pushes a function call onto a list. The list of saved -calls is executed after the surrounding function returns. Defer is commonly -used to simplify functions that perform various clean-up actions. -
- --For example, let's look at a function that opens two files and copies the -contents of one file to the other: -
- -{{code "/doc/progs/defer.go" `/func CopyFile/` `/STOP/`}} - --This works, but there is a bug. If the call to os.Create fails, the -function will return without closing the source file. This can be easily -remedied by putting a call to src.Close before the second return statement, -but if the function were more complex the problem might not be so easily -noticed and resolved. By introducing defer statements we can ensure that the -files are always closed: -
- -{{code "/doc/progs/defer2.go" `/func CopyFile/` `/STOP/`}} - --Defer statements allow us to think about closing each file right after opening -it, guaranteeing that, regardless of the number of return statements in the -function, the files will be closed. -
- --The behavior of defer statements is straightforward and predictable. There are -three simple rules: -
- --1. A deferred function's arguments are evaluated when the defer statement is -evaluated. -
- --In this example, the expression "i" is evaluated when the Println call is -deferred. The deferred call will print "0" after the function returns. -
- -{{code "/doc/progs/defer.go" `/func a/` `/STOP/`}} - --2. Deferred function calls are executed in Last In First Out order -after the surrounding function returns. -
- --This function prints "3210": -
- -{{code "/doc/progs/defer.go" `/func b/` `/STOP/`}} - --3. Deferred functions may read and assign to the returning function's named -return values. -
- --In this example, a deferred function increments the return value i after -the surrounding function returns. Thus, this function returns 2: -
- -{{code "/doc/progs/defer.go" `/func c/` `/STOP/`}} - --This is convenient for modifying the error return value of a function; we will -see an example of this shortly. -
- --Panic is a built-in function that stops the ordinary flow of control and -begins panicking. When the function F calls panic, execution of F stops, -any deferred functions in F are executed normally, and then F returns to its -caller. To the caller, F then behaves like a call to panic. The process -continues up the stack until all functions in the current goroutine have -returned, at which point the program crashes. Panics can be initiated by -invoking panic directly. They can also be caused by runtime errors, such as -out-of-bounds array accesses. -
- --Recover is a built-in function that regains control of a panicking -goroutine. Recover is only useful inside deferred functions. During normal -execution, a call to recover will return nil and have no other effect. If the -current goroutine is panicking, a call to recover will capture the value given -to panic and resume normal execution. -
- --Here's an example program that demonstrates the mechanics of panic and defer: -
- -{{code "/doc/progs/defer2.go" `/package main/` `/STOP/`}} - --The function g takes the int i, and panics if i is greater than 3, or else it -calls itself with the argument i+1. The function f defers a function that calls -recover and prints the recovered value (if it is non-nil). Try to picture what -the output of this program might be before reading on. -
- --The program will output: -
- -Calling g. -Printing in g 0 -Printing in g 1 -Printing in g 2 -Printing in g 3 -Panicking! -Defer in g 3 -Defer in g 2 -Defer in g 1 -Defer in g 0 -Recovered in f 4 -Returned normally from f.- -
-If we remove the deferred function from f the panic is not recovered and -reaches the top of the goroutine's call stack, terminating the program. This -modified program will output: -
- -Calling g. -Printing in g 0 -Printing in g 1 -Printing in g 2 -Printing in g 3 -Panicking! -Defer in g 3 -Defer in g 2 -Defer in g 1 -Defer in g 0 -panic: 4 - -panic PC=0x2a9cd8 -[stack trace omitted]- -
-For a real-world example of panic and recover, see the -json package from the Go standard library. -It decodes JSON-encoded data with a set of recursive functions. -When malformed JSON is encountered, the parser calls panic to unwind the -stack to the top-level function call, which recovers from the panic and returns -an appropriate error value (see the 'error' and 'unmarshal' methods of -the decodeState type in -decode.go). -
- --The convention in the Go libraries is that even when a package uses panic -internally, its external API still presents explicit error return values. -
- --Other uses of defer (beyond the file.Close example given earlier) -include releasing a mutex: -
- -mu.Lock() -defer mu.Unlock()- -
-printing a footer: -
- -printHeader() -defer printFooter()- -
-and more. -
- --In summary, the defer statement (with or without panic and recover) provides an -unusual and powerful mechanism for control flow. It can be used to model a -number of features implemented by special-purpose structures in other -programming languages. Try it out. -
diff --git a/doc/articles/error_handling.html b/doc/articles/error_handling.html deleted file mode 100644 index 6ba05ac1da..0000000000 --- a/doc/articles/error_handling.html +++ /dev/null @@ -1,316 +0,0 @@ - - -
-If you have written any Go code you have probably encountered the built-in
-error type. Go code uses error values to
-indicate an abnormal state. For example, the os.Open function
-returns a non-nil error value when it fails to open a file.
-
-The following code uses os.Open to open a file. If an error
-occurs it calls log.Fatal to print the error message and stop.
-
-You can get a lot done in Go knowing just this about the error
-type, but in this article we'll take a closer look at error and
-discuss some good practices for error handling in Go.
-
-The error type -
- -
-The error type is an interface type. An error
-variable represents any value that can describe itself as a string. Here is the
-interface's declaration:
-
type error interface {
- Error() string
-}
-
-
-The error type, as with all built in types, is
-predeclared in the
-universe block.
-
-The most commonly-used error implementation is the
-errors package's unexported errorString type.
-
-You can construct one of these values with the errors.New
-function. It takes a string that it converts to an errors.errorString
-and returns as an error value.
-
-Here's how you might use errors.New:
-
-A caller passing a negative argument to Sqrt receives a non-nil
-error value (whose concrete representation is an
-errors.errorString value). The caller can access the error string
-("math: square root of...") by calling the error's
-Error method, or by just printing it:
-
-The fmt package formats an error value
-by calling its Error() string method.
-
-It is the error implementation's responsibility to summarize the context.
-The error returned by os.Open formats as "open /etc/passwd:
-permission denied," not just "permission denied." The error returned by our
-Sqrt is missing information about the invalid argument.
-
-To add that information, a useful function is the fmt package's
-Errorf. It formats a string according to Printf's
-rules and returns it as an error created by
-errors.New.
-
-In many cases fmt.Errorf is good enough, but since
-error is an interface, you can use arbitrary data structures as
-error values, to allow callers to inspect the details of the error.
-
-For instance, our hypothetical callers might want to recover the invalid
-argument passed to Sqrt. We can enable that by defining a new
-error implementation instead of using errors.errorString:
-
-A sophisticated caller can then use a
-type assertion to check for a
-NegativeSqrtError and handle it specially, while callers that just
-pass the error to fmt.Println or log.Fatal will see
-no change in behavior.
-
-As another example, the json package specifies a
-SyntaxError type that the json.Decode function
-returns when it encounters a syntax error parsing a JSON blob.
-
-The Offset field isn't even shown in the default formatting of the
-error, but callers can use it to add file and line information to their error
-messages:
-
-(This is a slightly simplified version of some -actual code -from the Camlistore project.) -
- -
-The error interface requires only a Error method;
-specific error implementations might have additional methods. For instance, the
-net package returns errors of type
-error, following the usual convention, but some of the error
-implementations have additional methods defined by the net.Error
-interface:
-
package net
-
-type Error interface {
- error
- Timeout() bool // Is the error a timeout?
- Temporary() bool // Is the error temporary?
-}
-
-
-Client code can test for a net.Error with a type assertion and
-then distinguish transient network errors from permanent ones. For instance, a
-web crawler might sleep and retry when it encounters a temporary error and give
-up otherwise.
-
-Simplifying repetitive error handling -
- --In Go, error handling is important. The language's design and conventions -encourage you to explicitly check for errors where they occur (as distinct from -the convention in other languages of throwing exceptions and sometimes catching -them). In some cases this makes Go code verbose, but fortunately there are some -techniques you can use to minimize repetitive error handling. -
- --Consider an App Engine -application with an HTTP handler that retrieves a record from the datastore and -formats it with a template. -
- -{{code "/doc/progs/error2.go" `/func init/` `/STOP/`}} - -
-This function handles errors returned by the datastore.Get
-function and viewTemplate's Execute method. In both
-cases, it presents a simple error message to the user with the HTTP status code
-500 ("Internal Server Error"). This looks like a manageable amount of code, but
-add some more HTTP handlers and you quickly end up with many copies of
-identical error handling code.
-
-To reduce the repetition we can define our own HTTP appHandler
-type that includes an error return value:
-
-Then we can change our viewRecord function to return errors:
-
-This is simpler than the original version, but the http package doesn't understand functions that return
-error.
-To fix this we can implement the http.Handler interface's
-ServeHTTP method on appHandler:
-
-The ServeHTTP method calls the appHandler function
-and displays the returned error (if any) to the user. Notice that the method's
-receiver, fn, is a function. (Go can do that!) The method invokes
-the function by calling the receiver in the expression fn(w, r).
-
-Now when registering viewRecord with the http package we use the
-Handle function (instead of HandleFunc) as
-appHandler is an http.Handler (not an
-http.HandlerFunc).
-
-With this basic error handling infrastructure in place, we can make it more -user friendly. Rather than just displaying the error string, it would be better -to give the user a simple error message with an appropriate HTTP status code, -while logging the full error to the App Engine developer console for debugging -purposes. -
- -
-To do this we create an appError struct containing an
-error and some other fields:
-
-Next we modify the appHandler type to return *appError values:
-
-(It's usually a mistake to pass back the concrete type of an error rather than
-error,
-for reasons discussed in the Go FAQ,
-but it's the right thing to do here because ServeHTTP is the only
-place that sees the value and uses its contents.)
-
-And make appHandler's ServeHTTP method display the
-appError's Message to the user with the correct HTTP
-status Code and log the full Error to the developer
-console:
-
-Finally, we update viewRecord to the new function signature and
-have it return more context when it encounters an error:
-
-This version of viewRecord is the same length as the original, but
-now each of those lines has specific meaning and we are providing a friendlier
-user experience.
-
-It doesn't end there; we can further improve the error handling in our -application. Some ideas: -
- -appError that stores the
-stack trace for easier debugging,
-appHandler, logging the error
-to the console as "Critical," while telling the user "a serious error
-has occurred." This is a nice touch to avoid exposing the user to inscrutable
-error messages caused by programming errors.
-See the Defer, Panic, and Recover
-article for more details.
--Conclusion -
- --Proper error handling is an essential requirement of good software. By -employing the techniques described in this post you should be able to write -more reliable and succinct Go code. -
diff --git a/doc/articles/gobs_of_data.html b/doc/articles/gobs_of_data.html deleted file mode 100644 index 6b836b2c36..0000000000 --- a/doc/articles/gobs_of_data.html +++ /dev/null @@ -1,315 +0,0 @@ - - --To transmit a data structure across a network or to store it in a file, it must -be encoded and then decoded again. There are many encodings available, of -course: JSON, -XML, Google's -protocol buffers, and more. -And now there's another, provided by Go's gob -package. -
- --Why define a new encoding? It's a lot of work and redundant at that. Why not -just use one of the existing formats? Well, for one thing, we do! Go has -packages supporting all the encodings just mentioned (the -protocol buffer package is in -a separate repository but it's one of the most frequently downloaded). And for -many purposes, including communicating with tools and systems written in other -languages, they're the right choice. -
- --But for a Go-specific environment, such as communicating between two servers -written in Go, there's an opportunity to build something much easier to use and -possibly more efficient. -
- --Gobs work with the language in a way that an externally-defined, -language-independent encoding cannot. At the same time, there are lessons to be -learned from the existing systems. -
- --Goals -
- --The gob package was designed with a number of goals in mind. -
- --First, and most obvious, it had to be very easy to use. First, because Go has -reflection, there is no need for a separate interface definition language or -"protocol compiler". The data structure itself is all the package should need -to figure out how to encode and decode it. On the other hand, this approach -means that gobs will never work as well with other languages, but that's OK: -gobs are unashamedly Go-centric. -
- --Efficiency is also important. Textual representations, exemplified by XML and -JSON, are too slow to put at the center of an efficient communications network. -A binary encoding is necessary. -
- --Gob streams must be self-describing. Each gob stream, read from the beginning, -contains sufficient information that the entire stream can be parsed by an -agent that knows nothing a priori about its contents. This property means that -you will always be able to decode a gob stream stored in a file, even long -after you've forgotten what data it represents. -
- --There were also some things to learn from our experiences with Google protocol -buffers. -
- --Protocol buffer misfeatures -
- --Protocol buffers had a major effect on the design of gobs, but have three -features that were deliberately avoided. (Leaving aside the property that -protocol buffers aren't self-describing: if you don't know the data definition -used to encode a protocol buffer, you might not be able to parse it.) -
- --First, protocol buffers only work on the data type we call a struct in Go. You -can't encode an integer or array at the top level, only a struct with fields -inside it. That seems a pointless restriction, at least in Go. If all you want -to send is an array of integers, why should you have to put it into a -struct first? -
- -
-Next, a protocol buffer definition may specify that fields T.x and
-T.y are required to be present whenever a value of type
-T is encoded or decoded. Although such required fields may seem
-like a good idea, they are costly to implement because the codec must maintain a
-separate data structure while encoding and decoding, to be able to report when
-required fields are missing. They're also a maintenance problem. Over time, one
-may want to modify the data definition to remove a required field, but that may
-cause existing clients of the data to crash. It's better not to have them in the
-encoding at all. (Protocol buffers also have optional fields. But if we don't
-have required fields, all fields are optional and that's that. There will be
-more to say about optional fields a little later.)
-
-The third protocol buffer misfeature is default values. If a protocol buffer -omits the value for a "defaulted" field, then the decoded structure behaves as -if the field were set to that value. This idea works nicely when you have -getter and setter methods to control access to the field, but is harder to -handle cleanly when the container is just a plain idiomatic struct. Required -fields are also tricky to implement: where does one define the default values, -what types do they have (is text UTF-8? uninterpreted bytes? how many bits in a -float?) and despite the apparent simplicity, there were a number of -complications in their design and implementation for protocol buffers. We -decided to leave them out of gobs and fall back to Go's trivial but effective -defaulting rule: unless you set something otherwise, it has the "zero value" -for that type - and it doesn't need to be transmitted. -
- --So gobs end up looking like a sort of generalized, simplified protocol buffer. -How do they work? -
- --Values -
- -
-The encoded gob data isn't about int8s and uint16s.
-Instead, somewhat analogous to constants in Go, its integer values are abstract,
-sizeless numbers, either signed or unsigned. When you encode an
-int8, its value is transmitted as an unsized, variable-length
-integer. When you encode an int64, its value is also transmitted as
-an unsized, variable-length integer. (Signed and unsigned are treated
-distinctly, but the same unsized-ness applies to unsigned values too.) If both
-have the value 7, the bits sent on the wire will be identical. When the receiver
-decodes that value, it puts it into the receiver's variable, which may be of
-arbitrary integer type. Thus an encoder may send a 7 that came from an
-int8, but the receiver may store it in an int64. This
-is fine: the value is an integer and as a long as it fits, everything works. (If
-it doesn't fit, an error results.) This decoupling from the size of the variable
-gives some flexibility to the encoding: we can expand the type of the integer
-variable as the software evolves, but still be able to decode old data.
-
-This flexibility also applies to pointers. Before transmission, all pointers are
-flattened. Values of type int8, *int8,
-**int8, ****int8, etc. are all transmitted as an
-integer value, which may then be stored in int of any size, or
-*int, or ******int, etc. Again, this allows for
-flexibility.
-
-Flexibility also happens because, when decoding a struct, only those fields -that are sent by the encoder are stored in the destination. Given the value -
- -{{code "/doc/progs/gobs1.go" `/type T/` `/STOP/`}} - -
-the encoding of t sends only the 7 and 8. Because it's zero, the
-value of Y isn't even sent; there's no need to send a zero value.
-
-The receiver could instead decode the value into this structure: -
- -{{code "/doc/progs/gobs1.go" `/type U/` `/STOP/`}} - -
-and acquire a value of u with only X set (to the
-address of an int8 variable set to 7); the Z field is
-ignored - where would you put it? When decoding structs, fields are matched by
-name and compatible type, and only fields that exist in both are affected. This
-simple approach finesses the "optional field" problem: as the type
-T evolves by adding fields, out of date receivers will still
-function with the part of the type they recognize. Thus gobs provide the
-important result of optional fields - extensibility - without any additional
-mechanism or notation.
-
-From integers we can build all the other types: bytes, strings, arrays, slices, -maps, even floats. Floating-point values are represented by their IEEE 754 -floating-point bit pattern, stored as an integer, which works fine as long as -you know their type, which we always do. By the way, that integer is sent in -byte-reversed order because common values of floating-point numbers, such as -small integers, have a lot of zeros at the low end that we can avoid -transmitting. -
- --One nice feature of gobs that Go makes possible is that they allow you to define -your own encoding by having your type satisfy the -GobEncoder and -GobDecoder interfaces, in a manner -analogous to the JSON package's -Marshaler and -Unmarshaler and also to the -Stringer interface from -package fmt. This facility makes it possible to -represent special features, enforce constraints, or hide secrets when you -transmit data. See the documentation for -details. -
- --Types on the wire -
- --The first time you send a given type, the gob package includes in the data -stream a description of that type. In fact, what happens is that the encoder is -used to encode, in the standard gob encoding format, an internal struct that -describes the type and gives it a unique number. (Basic types, plus the layout -of the type description structure, are predefined by the software for -bootstrapping.) After the type is described, it can be referenced by its type -number. -
- -
-Thus when we send our first type T, the gob encoder sends a
-description of T and tags it with a type number, say 127. All
-values, including the first, are then prefixed by that number, so a stream of
-T values looks like:
-
-("define type id" 127, definition of type T)(127, T value)(127, T value), ...
-
-
--These type numbers make it possible to describe recursive types and send values -of those types. Thus gobs can encode types such as trees: -
- -{{code "/doc/progs/gobs1.go" `/type Node/` `/STOP/`}} - --(It's an exercise for the reader to discover how the zero-defaulting rule makes -this work, even though gobs don't represent pointers.) -
- --With the type information, a gob stream is fully self-describing except for the -set of bootstrap types, which is a well-defined starting point. -
- --Compiling a machine -
- --The first time you encode a value of a given type, the gob package builds a -little interpreted machine specific to that data type. It uses reflection on -the type to construct that machine, but once the machine is built it does not -depend on reflection. The machine uses package unsafe and some trickery to -convert the data into the encoded bytes at high speed. It could use reflection -and avoid unsafe, but would be significantly slower. (A similar high-speed -approach is taken by the protocol buffer support for Go, whose design was -influenced by the implementation of gobs.) Subsequent values of the same type -use the already-compiled machine, so they can be encoded right away. -
- --Decoding is similar but harder. When you decode a value, the gob package holds -a byte slice representing a value of a given encoder-defined type to decode, -plus a Go value into which to decode it. The gob package builds a machine for -that pair: the gob type sent on the wire crossed with the Go type provided for -decoding. Once that decoding machine is built, though, it's again a -reflectionless engine that uses unsafe methods to get maximum speed. -
- --Use -
- --There's a lot going on under the hood, but the result is an efficient, -easy-to-use encoding system for transmitting data. Here's a complete example -showing differing encoded and decoded types. Note how easy it is to send and -receive values; all you need to do is present values and variables to the -gob package and it does all the work. -
- -{{code "/doc/progs/gobs2.go" `/package main/` `$`}} - --You can compile and run this example code in the -Go Playground. -
- --The rpc package builds on gobs to turn this -encode/decode automation into transport for method calls across the network. -That's a subject for another article. -
- --Details -
- --The gob package documentation, especially the -file doc.go, expands on many of the -details described here and includes a full worked example showing how the -encoding represents data. If you are interested in the innards of the gob -implementation, that's a good place to start. -
diff --git a/doc/articles/godoc_documenting_go_code.html b/doc/articles/godoc_documenting_go_code.html deleted file mode 100644 index 3f4e3228c7..0000000000 --- a/doc/articles/godoc_documenting_go_code.html +++ /dev/null @@ -1,147 +0,0 @@ - - --The Go project takes documentation seriously. Documentation is a huge part of -making software accessible and maintainable. Of course it must be well-written -and accurate, but it also must be easy to write and to maintain. Ideally, it -should be coupled to the code itself so the documentation evolves along with the -code. The easier it is for programmers to produce good documentation, the better -for everyone. -
- --To that end, we have developed the godoc documentation -tool. This article describes godoc's approach to documentation, and explains how -you can use our conventions and tools to write good documentation for your own -projects. -
- --Godoc parses Go source code - including comments - and produces documentation as -HTML or plain text. The end result is documentation tightly coupled with the -code it documents. For example, through godoc's web interface you can navigate -from a function's documentation to its -implementation with one click. -
- --Godoc is conceptually related to Python's -Docstring and Java's -Javadoc, -but its design is simpler. The comments read by godoc are not language -constructs (as with Docstring) nor must they have their own machine-readable -syntax (as with Javadoc). Godoc comments are just good comments, the sort you -would want to read even if godoc didn't exist. -
- -
-The convention is simple: to document a type, variable, constant, function, or
-even a package, write a regular comment directly preceding its declaration, with
-no intervening blank line. Godoc will then present that comment as text
-alongside the item it documents. For example, this is the documentation for the
-fmt package's Fprint
-function:
-
-Notice this comment is a complete sentence that begins with the name of the -element it describes. This important convention allows us to generate -documentation in a variety of formats, from plain text to HTML to UNIX man -pages, and makes it read better when tools truncate it for brevity, such as when -they extract the first line or sentence. -
- -
-Comments on package declarations should provide general package documentation.
-These comments can be short, like the sort
-package's brief description:
-
-They can also be detailed like the gob
-package's overview. That package uses another convention for packages
-that need large amounts of introductory documentation: the package comment is
-placed in its own file, doc.go, which
-contains only those comments and a package clause.
-
-When writing package comments of any size, keep in mind that their first -sentence will appear in godoc's package list. -
- -
-Comments that are not adjacent to a top-level declaration are omitted from
-godoc's output, with one notable exception. Top-level comments that begin with
-the word "BUG(who)" are recognized as known bugs, and included in
-the "Bugs" section of the package documentation. The "who" part should be the
-user name of someone who could provide more information. For example, this is a
-known issue from the sync/atomic package:
-
-// BUG(rsc): On x86-32, the 64-bit functions use instructions -// unavailable before the Pentium MMX. On both ARM and x86-32, it is the -// caller's responsibility to arrange for 64-bit alignment of 64-bit -// words accessed atomically. -- -
-Godoc treats executable commands in the same way. It looks for a comment on
-package main, which is sometimes put in a separate file called doc.go.
-For example, see the
-godoc documentation and its corresponding
-doc.go file.
-
-There are a few formatting rules that Godoc uses when converting comments to -HTML: -
- --Note that none of these rules requires you to do anything out of the ordinary. -
- --In fact, the best thing about godoc's minimal approach is how easy it is to use. -As a result, a lot of Go code, including all of the standard library, already -follows the conventions. -
- -
-Your own code can present good documentation just by having comments as
-described above. Any Go packages installed inside $GOROOT/src/pkg
-and any GOPATH work spaces will already be accessible via godoc's
-command-line and HTTP interfaces, and you can specify additional paths for
-indexing via the -path flag or just by running "godoc ."
-in the source directory. See the godoc documentation
-for more details.
-
-Godoc recognizes example functions written according to the
-testing package's naming
-conventions and presents them appropriately.
-
-Newcomers to Go wonder why the declaration syntax is different from the -tradition established in the C family. In this post we'll compare the -two approaches and explain why Go's declarations look as they do. -
- --C syntax -
- --First, let's talk about C syntax. C took an unusual and clever approach -to declaration syntax. Instead of describing the types with special -syntax, one writes an expression involving the item being declared, and -states what type that expression will have. Thus -
- --int x; -- -
-declares x to be an int: the expression 'x' will have type int. In -general, to figure out how to write the type of a new variable, write an -expression involving that variable that evaluates to a basic type, then -put the basic type on the left and the expression on the right. -
- --Thus, the declarations -
- --int *p; -int a[3]; -- -
-state that p is a pointer to int because '*p' has type int, and that a -is an array of ints because a[3] (ignoring the particular index value, -which is punned to be the size of the array) has type int. -
- --What about functions? Originally, C's function declarations wrote the -types of the arguments outside the parens, like this: -
- -
-int main(argc, argv)
- int argc;
- char *argv[];
-{ /* ... */ }
-
-
--Again, we see that main is a function because the expression main(argc, -argv) returns an int. In modern notation we'd write -
- -
-int main(int argc, char *argv[]) { /* ... */ }
-
-
--but the basic structure is the same. -
- --This is a clever syntactic idea that works well for simple types but can -get confusing fast. The famous example is declaring a function pointer. -Follow the rules and you get this: -
- --int (*fp)(int a, int b); -- -
-Here, fp is a pointer to a function because if you write the expression -(*fp)(a, b) you'll call a function that returns int. What if one of fp's -arguments is itself a function? -
- --int (*fp)(int (*ff)(int x, int y), int b) -- -
-That's starting to get hard to read. -
- --Of course, we can leave out the name of the parameters when we declare a -function, so main can be declared -
- --int main(int, char *[]) -- -
-Recall that argv is declared like this, -
- --char *argv[] -- -
-so you drop the name from the middle of its declaration to construct -its type. It's not obvious, though, that you declare something of type -char *[] by putting its name in the middle. -
- --And look what happens to fp's declaration if you don't name the -parameters: -
- --int (*fp)(int (*)(int, int), int) -- -
-Not only is it not obvious where to put the name inside -
- --int (*)(int, int) -- -
-it's not exactly clear that it's a function pointer declaration at all. -And what if the return type is a function pointer? -
- --int (*(*fp)(int (*)(int, int), int))(int, int) -- -
-It's hard even to see that this declaration is about fp. -
- --You can construct more elaborate examples but these should illustrate -some of the difficulties that C's declaration syntax can introduce. -
- --There's one more point that needs to be made, though. Because type and -declaration syntax are the same, it can be difficult to parse -expressions with types in the middle. This is why, for instance, C casts -always parenthesize the type, as in -
- --(int)M_PI -- -
-Go syntax -
- --Languages outside the C family usually use a distinct type syntax in -declarations. Although it's a separate point, the name usually comes -first, often followed by a colon. Thus our examples above become -something like (in a fictional but illustrative language) -
- --x: int -p: pointer to int -a: array[3] of int -- -
-These declarations are clear, if verbose - you just read them left to -right. Go takes its cue from here, but in the interests of brevity it -drops the colon and removes some of the keywords: -
- --x int -p *int -a [3]int -- -
-There is no direct correspondence between the look of [3]int and how to -use a in an expression. (We'll come back to pointers in the next -section.) You gain clarity at the cost of a separate syntax. -
- --Now consider functions. Let's transcribe the declaration for main, even -though the main function in Go takes no arguments: -
- --func main(argc int, argv *[]byte) int -- -
-Superficially that's not much different from C, but it reads well from -left to right: -
- --function main takes an int and a pointer to a slice of bytes and returns an int. -
- --Drop the parameter names and it's just as clear - they're always first -so there's no confusion. -
- --func main(int, *[]byte) int -- -
-One value of this left-to-right style is how well it works as the types -become more complex. Here's a declaration of a function variable -(analogous to a function pointer in C): -
- --f func(func(int,int) int, int) int -- -
-Or if f returns a function: -
- --f func(func(int,int) int, int) func(int, int) int -- -
-It still reads clearly, from left to right, and it's always obvious -which name is being declared - the name comes first. -
- --The distinction between type and expression syntax makes it easy to -write and invoke closures in Go: -
- -
-sum := func(a, b int) int { return a+b } (3, 4)
-
-
--Pointers -
- --Pointers are the exception that proves the rule. Notice that in arrays -and slices, for instance, Go's type syntax puts the brackets on the left -of the type but the expression syntax puts them on the right of the -expression: -
- --var a []int -x = a[1] -- -
-For familiarity, Go's pointers use the * notation from C, but we could -not bring ourselves to make a similar reversal for pointer types. Thus -pointers work like this -
- --var p *int -x = *p -- -
-We couldn't say -
- --var p *int -x = p* -- -
-because that postfix * would conflate with multiplication. We could have -used the Pascal ^, for example: -
- --var p ^int -x = p^ -- -
-and perhaps we should have (and chosen another operator for xor), -because the prefix asterisk on both types and expressions complicates -things in a number of ways. For instance, although one can write -
- -
-[]int("hi")
-
-
--as a conversion, one must parenthesize the type if it starts with a *: -
- --(*int)(nil) -- -
-Had we been willing to give up * as pointer syntax, those parentheses -would be unnecessary. -
- --So Go's pointer syntax is tied to the familiar C form, but those ties -mean that we cannot break completely from using parentheses to -disambiguate types and expressions in the grammar. -
- --Overall, though, we believe Go's type syntax is easier to understand -than C's, especially when things get complicated. -
- --Notes -
- --Go's declarations read left to right. It's been pointed out that C's -read in a spiral! See -The "Clockwise/Spiral Rule" by David Anderson. -
diff --git a/doc/articles/image-20.png b/doc/articles/image-20.png deleted file mode 100644 index 063e430645..0000000000 Binary files a/doc/articles/image-20.png and /dev/null differ diff --git a/doc/articles/image-2a.png b/doc/articles/image-2a.png deleted file mode 100644 index 3f1c0afff8..0000000000 Binary files a/doc/articles/image-2a.png and /dev/null differ diff --git a/doc/articles/image-2b.png b/doc/articles/image-2b.png deleted file mode 100644 index 32b2470114..0000000000 Binary files a/doc/articles/image-2b.png and /dev/null differ diff --git a/doc/articles/image-2c.png b/doc/articles/image-2c.png deleted file mode 100644 index f9abce5b52..0000000000 Binary files a/doc/articles/image-2c.png and /dev/null differ diff --git a/doc/articles/image-2d.png b/doc/articles/image-2d.png deleted file mode 100644 index ed0a9f92c4..0000000000 Binary files a/doc/articles/image-2d.png and /dev/null differ diff --git a/doc/articles/image-2e.png b/doc/articles/image-2e.png deleted file mode 100644 index 483b208e3a..0000000000 Binary files a/doc/articles/image-2e.png and /dev/null differ diff --git a/doc/articles/image-2f.png b/doc/articles/image-2f.png deleted file mode 100644 index 3dce02d5f4..0000000000 Binary files a/doc/articles/image-2f.png and /dev/null differ diff --git a/doc/articles/image-package-01.png b/doc/articles/image-package-01.png deleted file mode 100644 index aad9b12434..0000000000 Binary files a/doc/articles/image-package-01.png and /dev/null differ diff --git a/doc/articles/image-package-02.png b/doc/articles/image-package-02.png deleted file mode 100644 index 3dd4692f3e..0000000000 Binary files a/doc/articles/image-package-02.png and /dev/null differ diff --git a/doc/articles/image-package-03.png b/doc/articles/image-package-03.png deleted file mode 100644 index 5bc0bf732d..0000000000 Binary files a/doc/articles/image-package-03.png and /dev/null differ diff --git a/doc/articles/image-package-04.png b/doc/articles/image-package-04.png deleted file mode 100644 index 393dc1207e..0000000000 Binary files a/doc/articles/image-package-04.png and /dev/null differ diff --git a/doc/articles/image-package-05.png b/doc/articles/image-package-05.png deleted file mode 100644 index 54c47b67bf..0000000000 Binary files a/doc/articles/image-package-05.png and /dev/null differ diff --git a/doc/articles/image_draw.html b/doc/articles/image_draw.html deleted file mode 100644 index 71658cf920..0000000000 --- a/doc/articles/image_draw.html +++ /dev/null @@ -1,222 +0,0 @@ - - --Package image/draw defines -only one operation: drawing a source image onto a destination -image, through an optional mask image. This one operation is -surprisingly versatile and can perform a number of common image -manipulation tasks elegantly and efficiently. -
- -
-Composition is performed pixel by pixel in the style of the Plan 9
-graphics library and the X Render extension. The model is based on
-the classic "Compositing Digital Images" paper by Porter and Duff,
-with an additional mask parameter: dst = (src IN mask) OP dst.
-For a fully opaque mask, this reduces to the original Porter-Duff
-formula: dst = src OP dst. In Go, a nil mask image is equivalent
-to an infinitely sized, fully opaque mask image.
-
-The Porter-Duff paper presented
-12 different composition operators,
-but with an explicit mask, only 2 of these are needed in practice:
-source-over-destination and source. In Go, these operators are
-represented by the Over and Src constants. The Over operator
-performs the natural layering of a source image over a destination
-image: the change to the destination image is smaller where the
-source (after masking) is more transparent (that is, has lower
-alpha). The Src operator merely copies the source (after masking)
-with no regard for the destination image's original content. For
-fully opaque source and mask images, the two operators produce the
-same output, but the Src operator is usually faster.
-
Geometric Alignment
- -
-Composition requires associating destination pixels with source and
-mask pixels. Obviously, this requires destination, source and mask
-images, and a composition operator, but it also requires specifying
-what rectangle of each image to use. Not every drawing should write
-to the entire destination: when updating an animating image, it is
-more efficient to only draw the parts of the image that have
-changed. Not every drawing should read from the entire source: when
-using a sprite that combines many small images into one large one,
-only a part of the image is needed. Not every drawing should read
-from the entire mask: a mask image that collects a font's glyphs is
-similar to a sprite. Thus, drawing also needs to know three
-rectangles, one for each image. Since each rectangle has the same
-width and height, it suffices to pass a destination rectangle `r`
-and two points sp and mp: the source rectangle is equal to r
-translated so that r.Min in the destination image aligns with
-sp in the source image, and similarly for mp. The effective
-rectangle is also clipped to each image's bounds in their
-respective co-ordinate space.
-
-
-
-The DrawMask
-function takes seven arguments, but an explicit mask and mask-point
-are usually unnecessary, so the
-Draw function takes five:
-
-// Draw calls DrawMask with a nil mask. -func Draw(dst Image, r image.Rectangle, src image.Image, sp image.Point, op Op) -func DrawMask(dst Image, r image.Rectangle, src image.Image, sp image.Point, - mask image.Image, mp image.Point, op Op) -- -
-The destination image must be mutable, so the image/draw package
-defines a draw.Image
-interface which has a Set method.
-
Filling a Rectangle
- -
-To fill a rectangle with a solid color, use an image.Uniform
-source. The Uniform type re-interprets a Color as a
-practically infinite-sized Image of that color. For those
-familiar with the design of Plan 9's draw library, there is no need
-for an explicit "repeat bit" in Go's slice-based image types; the
-concept is subsumed by Uniform.
-
-To initialize a new image to all-blue: -
- -{{code "/doc/progs/image_draw.go" `/BLUE/` `/STOP/`}} - -
-To reset an image to transparent (or black, if the destination
-image's color model cannot represent transparency), use
-image.Transparent, which is an image.Uniform:
-
- -
-
Copying an Image
- -
-To copy from a rectangle sr in the source image to a rectangle
-starting at a point dp in the destination, convert the source
-rectangle into the destination image's co-ordinate space:
-
-Alternatively: -
- -{{code "/doc/progs/image_draw.go" `/RECT2/` `/STOP/`}} - -
-To copy the entire source image, use sr = src.Bounds().
-
- -
-
Scrolling an Image
- --Scrolling an image is just copying an image to itself, with -different destination and source rectangles. Overlapping -destination and source images are perfectly valid, just as Go's -built-in copy function can handle overlapping destination and -source slices. To scroll an image m by 20 pixels: -
- -{{code "/doc/progs/image_draw.go" `/SCROLL/` `/STOP/`}} - -
Converting an Image to RGBA
- -
-The result of decoding an image format might not be an
-image.RGBA: decoding a GIF results in an image.Paletted,
-decoding a JPEG results in a ycbcr.YCbCr, and the result of
-decoding a PNG depends on the image data. To convert any image to
-an image.RGBA:
-
- -
-
Drawing Through a Mask
- -
-To draw an image through a circular mask with center p and radius
-r:
-
- -
-
Drawing Font Glyphs
- -
-To draw a font glyph in blue starting from a point p, draw with
-an image.Uniform source and an image.Alpha mask. For
-simplicity, we aren't performing any sub-pixel positioning or
-rendering, or correcting for a font's height above a baseline.
-
- -
-
Performance
- -
-The image/draw package implementation demonstrates how to provide
-an image manipulation function that is both general purpose, yet
-efficient for common cases. The DrawMask function takes arguments
-of interface types, but immediately makes type assertions that its
-arguments are of specific struct types, corresponding to common
-operations like drawing one image.RGBA image onto another, or
-drawing an image.Alpha mask (such as a font glyph) onto an
-image.RGBA image. If a type assertion succeeds, that type
-information is used to run a specialized implementation of the
-general algorithm. If the assertions fail, the fallback code path
-uses the generic At and Set methods. The fast-paths are purely
-a performance optimization; the resultant destination image is the
-same either way. In practice, only a small number of special cases
-are necessary to support typical applications.
-
-The image and
-image/color packages define a number of types:
-color.Color and color.Model describe colors,
-image.Point and image.Rectangle describe basic 2-D
-geometry, and image.Image brings the two concepts together to
-represent a rectangular grid of colors. A
-separate article covers image
-composition with the image/draw package.
-
-Colors and Color Models -
- --Color is an interface that defines the minimal -method set of any type that can be considered a color: one that can be converted -to red, green, blue and alpha values. The conversion may be lossy, such as -converting from CMYK or YCbCr color spaces. -
- -{{code "/src/pkg/image/color/color.go" `/type Color interface/` `/^}/`}} - -
-There are three important subtleties about the return values. First, the red,
-green and blue are alpha-premultiplied: a fully saturated red that is also 25%
-transparent is represented by RGBA returning a 75% r. Second, the channels have
-a 16-bit effective range: 100% red is represented by RGBA returning an r of
-65535, not 255, so that converting from CMYK or YCbCr is not as lossy. Third,
-the type returned is uint32, even though the maximum value is 65535, to
-guarantee that multiplying two values together won't overflow. Such
-multiplications occur when blending two colors according to an alpha mask from a
-third color, in the style of
-Porter and Duff's
-classic algebra:
-
-dstr, dstg, dstb, dsta := dst.RGBA() -srcr, srcg, srcb, srca := src.RGBA() -_, _, _, m := mask.RGBA() -const M = 1<<16 - 1 -// The resultant red value is a blend of dstr and srcr, and ranges in [0, M]. -// The calculation for green, blue and alpha is similar. -dstr = (dstr*(M-m) + srcr*m) / M -- -
-The last line of that code snippet would have been more complicated if we worked
-with non-alpha-premultiplied colors, which is why Color uses
-alpha-premultiplied values.
-
-The image/color package also defines a number of concrete types that implement
-the Color interface. For example,
-RGBA is a struct that represents
-the classic "8 bits per channel" color.
-
-Note that the R field of an RGBA is an 8-bit
-alpha-premultiplied color in the range [0, 255]. RGBA satisfies the
-Color interface by multiplying that value by 0x101 to generate a
-16-bit alpha-premultiplied color in the range [0, 65535]. Similarly, the
-NRGBA struct type represents
-an 8-bit non-alpha-premultiplied color, as used by the PNG image format. When
-manipulating an NRGBA's fields directly, the values are
-non-alpha-premultiplied, but when calling the RGBA method, the
-return values are alpha-premultiplied.
-
-A Model is simply
-something that can convert Colors to other Colors, possibly lossily. For
-example, the GrayModel can convert any Color to a
-desaturated Gray. A
-Palette can convert any Color to one from a
-limited palette.
-
-Points and Rectangles -
- -
-A Point is an (x, y) co-ordinate
-on the integer grid, with axes increasing right and down. It is neither a pixel
-nor a grid square. A Point has no intrinsic width, height or
-color, but the visualizations below use a small colored square.
-
- -
-
-A Rectangle is an axis-aligned
-rectangle on the integer grid, defined by its top-left and bottom-right
-Point. A Rectangle also has no intrinsic color, but
-the visualizations below outline rectangles with a thin colored line, and call
-out their Min and Max Points.
-
-For convenience, image.Rect(x0, y0, x1, y1) is equivalent to
-image.Rectangle{image.Point{x0, y0}, image.Point{x1, y1}}, but is
-much easier to type.
-
-A Rectangle is inclusive at the top-left and exclusive at the
-bottom-right. For a Point p and a Rectangle r,
-p.In(r) if and only if
-r.Min.X <= p.X && p.X < r.Max.X, and similarly for Y. This is analogous to how
-a slice s[i0:i1] is inclusive at the low end and exclusive at the
-high end. (Unlike arrays and slices, a Rectangle often has a
-non-zero origin.)
-
- -
-
-Adding a Point to a Rectangle translates the
-Rectangle. Points and Rectangles are not restricted to be in the
-bottom-right quadrant.
-
- -
-
-Intersecting two Rectangles yields another Rectangle, which may be empty. -
- -
- -
-
-Points and Rectangles are passed and returned by value. A function that takes a
-Rectangle argument will be as efficient as a function that takes
-two Point arguments, or four int arguments.
-
-Images -
- -
-An Image maps every grid square in a
-Rectangle to a Color from a Model.
-"The pixel at (x, y)" refers to the color of the grid square defined by the
-points (x, y), (x+1, y), (x+1, y+1) and (x, y+1).
-
-A common mistake is assuming that an Image's bounds start at (0,
-0). For example, an animated GIF contains a sequence of Images, and each
-Image after the first typically only holds pixel data for the area
-that changed, and that area doesn't necessarily start at (0, 0). The correct
-way to iterate over an Image m's pixels looks like:
-
-b := m.Bounds()
-for y := b.Min.Y; y < b.Max.Y; y++ {
- for x := b.Min.X; x < b.Max.X; x++ {
- doStuffWith(m.At(x, y))
- }
-}
-
-
-
-Image implementations do not have to be based on an in-memory
-slice of pixel data. For example, a
-Uniform is an
-Image of enormous bounds and uniform color, whose in-memory
-representation is simply that color.
-
-Typically, though, programs will want an image based on a slice. Struct types
-like RGBA and
-Gray (which other packages refer
-to as image.RGBA and image.Gray) hold slices of pixel
-data and implement the Image interface.
-
-These types also provide a Set(x, y int, c color.Color) method
-that allows modifying the image one pixel at a time.
-
-If you're reading or writing a lot of pixel data, it can be more efficient, but
-more complicated, to access these struct type's Pix field directly.
-
-The slice-based Image implementations also provide a
-SubImage method, which returns an Image backed by the
-same array. Modifying the pixels of a sub-image will affect the pixels of the
-original image, analogous to how modifying the contents of a sub-slice
-s[i0:i1] will affect the contents of the original slice
-s.
-
 -
-{{code "/doc/progs/image_package6.go" `/m0 := image.New/` `/fmt.Println\(m0.Stride/`}}
-
-
-
-{{code "/doc/progs/image_package6.go" `/m0 := image.New/` `/fmt.Println\(m0.Stride/`}}
-
-
-For low-level code that works on an image's Pix field, be aware
-that ranging over Pix can affect pixels outside an image's bounds.
-In the example above, the pixels covered by m1.Pix are shaded in
-blue. Higher-level code, such as the At and Set
-methods or the image/draw package, will clip
-their operations to the image's bounds.
-
-Image Formats -
- -
-The standard package library supports a number of common image formats, such as
-GIF, JPEG and PNG. If you know the format of a source image file, you can
-decode from an io.Reader directly.
-
-import (
- "image/jpeg"
- "image/png"
- "io"
-)
-
-// convertJPEGToPNG converts from JPEG to PNG.
-func convertJPEGToPNG(w io.Writer, r io.Reader) error {
- img, err := jpeg.Decode(r)
- if err != nil {
- return err
- }
- return png.Encode(w, img)
-}
-
-
-
-If you have image data of unknown format, the
-image.Decode function can detect
-the format. The set of recognized formats is constructed at run time and is not
-limited to those in the standard package library. An image format package
-typically registers its format in an init function, and the main package will
-"underscore import" such a package solely for the side effect of format
-registration.
-
-import (
- "image"
- "image/png"
- "io"
-
- _ "code.google.com/p/vp8-go/webp"
- _ "image/jpeg"
-)
-
-// convertToPNG converts from any recognized format to PNG.
-func convertToPNG(w io.Writer, r io.Reader) error {
- img, _, err := image.Decode(r)
- if err != nil {
- return err
- }
- return png.Encode(w, img)
-}
-
diff --git a/doc/articles/index.html b/doc/articles/index.html
index 5f70734ecd..9ddd669731 100644
--- a/doc/articles/index.html
+++ b/doc/articles/index.html
@@ -3,5 +3,6 @@
}-->
-See the Documents page for a complete list of Go articles. +See the Documents page and the +Blog index for a complete list of Go articles.
diff --git a/doc/articles/json_and_go.html b/doc/articles/json_and_go.html deleted file mode 100644 index 8c4ef33a41..0000000000 --- a/doc/articles/json_and_go.html +++ /dev/null @@ -1,357 +0,0 @@ - - --JSON (JavaScript Object Notation) is a simple data interchange format. -Syntactically it resembles the objects and lists of JavaScript. It is most -commonly used for communication between web back-ends and JavaScript programs -running in the browser, but it is used in many other places, too. Its home page, -json.org, provides a wonderfully clear and concise -definition of the standard. -
- --With the json package it's a snap to read and -write JSON data from your Go programs. -
- --Encoding -
- -
-To encode JSON data we use the
-Marshal function.
-
-func Marshal(v interface{}) ([]byte, error)
-
-
-
-Given the Go data structure, Message,
-
-and an instance of Message
-
-we can marshal a JSON-encoded version of m using json.Marshal:
-
-If all is well, err will be nil and b
-will be a []byte containing this JSON data:
-
-b == []byte(`{"Name":"Alice","Body":"Hello","Time":1294706395881547000}`)
-
-
--Only data structures that can be represented as valid JSON will be encoded: -
- -map[string]T (where T is any Go type
-supported by the json package).
-Marshal
-to go into an infinite loop.
-nil).
--The json package only accesses the exported fields of struct types (those that -begin with an uppercase letter). Therefore only the exported fields of a struct -will be present in the JSON output. -
- --Decoding -
- -
-To decode JSON data we use the
-Unmarshal function.
-
-func Unmarshal(data []byte, v interface{}) error
-
-
--We must first create a place where the decoded data will be stored -
- -{{code "/doc/progs/json1.go" `/var m Message/`}} - -
-and call json.Unmarshal, passing it a []byte of JSON
-data and a pointer to m
-
-If b contains valid JSON that fits in m, after the
-call err will be nil and the data from b
-will have been stored in the struct m, as if by an assignment
-like:
-
-How does Unmarshal identify the fields in which to store the
-decoded data? For a given JSON key "Foo", Unmarshal
-will look through the destination struct's fields to find (in order of
-preference):
-
`json:"Foo"` (see the
-Go spec for more on struct tags),
-"Foo", or
-"FOO" or "FoO" or some other
-case-insensitive match of "Foo".
--What happens when the structure of the JSON data doesn't exactly match the Go -type? -
- -{{code "/doc/progs/json1.go" `/"Food":"Pickle"/` `/STOP/`}} - -
-Unmarshal will decode only the fields that it can find in the
-destination type. In this case, only the Name field of m will be
-populated, and the Food field will be ignored. This behavior is
-particularly useful when you wish to pick only a few specific fields out of a
-large JSON blob. It also means that any unexported fields in the destination
-struct will be unaffected by Unmarshal.
-
-But what if you don't know the structure of your JSON data beforehand? -
- -
-Generic JSON with interface{}
-
-The interface{} (empty interface) type describes an interface with
-zero methods. Every Go type implements at least zero methods and therefore
-satisfies the empty interface.
-
-The empty interface serves as a general container type: -
- -{{code "/doc/progs/json2.go" `/var i interface{}/` `/STOP/`}} - --A type assertion accesses the underlying concrete type: -
- -{{code "/doc/progs/json2.go" `/r := i/` `/STOP/`}} - --Or, if the underlying type is unknown, a type switch determines the type: -
- -{{code "/doc/progs/json2.go" `/switch v/` `/STOP/`}} - -
-The json package uses map[string]interface{} and
-[]interface{} values to store arbitrary JSON objects and arrays;
-it will happily unmarshal any valid JSON blob into a plain
-interface{} value. The default concrete Go types are:
-
bool for JSON booleans,
-float64 for JSON numbers,
-string for JSON strings, and
-nil for JSON null.
--Decoding arbitrary data -
- -
-Consider this JSON data, stored in the variable b:
-
-Without knowing this data's structure, we can decode it into an
-interface{} value with Unmarshal:
-
-At this point the Go value in f would be a map whose keys are
-strings and whose values are themselves stored as empty interface values:
-
-To access this data we can use a type assertion to access f's
-underlying map[string]interface{}:
-
-We can then iterate through the map with a range statement and use a type switch -to access its values as their concrete types: -
- -{{code "/doc/progs/json3.go" `/for k, v/` `/STOP/`}} - --In this way you can work with unknown JSON data while still enjoying the -benefits of type safety. -
- --Reference Types -
- --Let's define a Go type to contain the data from the previous example: -
- -{{code "/doc/progs/json4.go" `/type FamilyMember/` `/STOP/`}} - -{{code "/doc/progs/json4.go" `/var m FamilyMember/` `/STOP/`}} - -
-Unmarshaling that data into a FamilyMember value works as
-expected, but if we look closely we can see a remarkable thing has happened.
-With the var statement we allocated a FamilyMember struct, and
-then provided a pointer to that value to Unmarshal, but at that
-time the Parents field was a nil slice value. To
-populate the Parents field, Unmarshal allocated a new
-slice behind the scenes. This is typical of how Unmarshal works
-with the supported reference types (pointers, slices, and maps).
-
-Consider unmarshaling into this data structure: -
- -
-type Foo struct {
- Bar *Bar
-}
-
-
-
-If there were a Bar field in the JSON object,
-Unmarshal would allocate a new Bar and populate it.
-If not, Bar would be left as a nil pointer.
-
-From this a useful pattern arises: if you have an application that receives a -few distinct message types, you might define "receiver" structure like -
- -
-type IncomingMessage struct {
- Cmd *Command
- Msg *Message
-}
-
-
-
-and the sending party can populate the Cmd field and/or the
-Msg field of the top-level JSON object, depending on the type of
-message they want to communicate. Unmarshal, when decoding the
-JSON into an IncomingMessage struct, will only allocate the data
-structures present in the JSON data. To know which messages to process, the
-programmer need simply test that either Cmd or Msg is
-not nil.
-
-Streaming Encoders and Decoders -
- -
-The json package provides Decoder and Encoder types
-to support the common operation of reading and writing streams of JSON data.
-The NewDecoder and NewEncoder functions wrap the
-io.Reader and
-io.Writer interface types.
-
-func NewDecoder(r io.Reader) *Decoder -func NewEncoder(w io.Writer) *Encoder -- -
-Here's an example program that reads a series of JSON objects from standard
-input, removes all but the Name field from each object, and then
-writes the objects to standard output:
-
-Due to the ubiquity of Readers and Writers, these Encoder and
-Decoder types can be used in a broad range of scenarios, such as
-reading and writing to HTTP connections, WebSockets, or files.
-
-References -
- --For more information see the json package documentation. For an example usage of -json see the source files of the jsonrpc package. -
diff --git a/doc/articles/json_rpc_tale_of_interfaces.html b/doc/articles/json_rpc_tale_of_interfaces.html deleted file mode 100644 index 0db366f33a..0000000000 --- a/doc/articles/json_rpc_tale_of_interfaces.html +++ /dev/null @@ -1,78 +0,0 @@ - - --Here we present an example where Go's -interfaces made it -easy to refactor some existing code to make it more flexible and extensible. -Originally, the standard library's RPC package used -a custom wire format called gob. For a -particular application, we wanted to use JSON -as an alternate wire format. -
- --We first defined a pair of interfaces to describe the functionality of the -existing wire format, one for the client, and one for the server (depicted -below). -
- -
-type ServerCodec interface {
- ReadRequestHeader(*Request) error
- ReadRequestBody(interface{}) error
- WriteResponse(*Response, interface{}) error
- Close() error
-}
-
-
-
-On the server side, we then changed two internal function signatures to accept
-the ServerCodec interface instead of our existing
-gob.Encoder. Here's one of them:
-
-func sendResponse(sending *sync.Mutex, req *Request,
- reply interface{}, enc *gob.Encoder, errmsg string)
-
-
--became -
- -
-func sendResponse(sending *sync.Mutex, req *Request,
- reply interface{}, enc ServerCodec, errmsg string)
-
-
-
-We then wrote a trivial gobServerCodec wrapper to reproduce the
-original functionality. From there it is simple to build a
-jsonServerCodec.
-
-After some similar changes to the client side, this was the full extent of the -work we needed to do on the RPC package. This whole exercise took about 20 -minutes! After tidying up and testing the new code, the -final changeset -was submitted. -
- --In an inheritance-oriented language like Java or C++, the obvious path would be -to generalize the RPC class, and create JsonRPC and GobRPC subclasses. However, -this approach becomes tricky if you want to make a further generalization -orthogonal to that hierarchy. (For example, if you were to implement an -alternate RPC standard). In our Go package, we took a route that is both -conceptually simpler and requires less code be written or changed. -
- --A vital quality for any codebase is maintainability. As needs change, it is -essential to adapt your code easily and cleanly, lest it become unwieldy to work -with. We believe Go's lightweight, composition-oriented type system provides a -means of structuring code that scales. -
diff --git a/doc/articles/laws_of_reflection.html b/doc/articles/laws_of_reflection.html deleted file mode 100644 index 57a769692a..0000000000 --- a/doc/articles/laws_of_reflection.html +++ /dev/null @@ -1,649 +0,0 @@ - - --Reflection in computing is the -ability of a program to examine its own structure, particularly -through types; it's a form of metaprogramming. It's also a great -source of confusion. -
- --In this article we attempt to clarify things by explaining how -reflection works in Go. Each language's reflection model is -different (and many languages don't support it at all), but -this article is about Go, so for the rest of this article the word -"reflection" should be taken to mean "reflection in Go". -
- -Types and interfaces
- --Because reflection builds on the type system, let's start with a -refresher about types in Go. -
- -
-Go is statically typed. Every variable has a static type, that is,
-exactly one type known and fixed at compile time: int,
-float32, *MyType, []byte,
-and so on. If we declare
-
-then i has type int and j
-has type MyInt. The variables i and
-j have distinct static types and, although they have
-the same underlying type, they cannot be assigned to one another
-without a conversion.
-
-One important category of type is interface types, which represent
-fixed sets of methods. An interface variable can store any concrete
-(non-interface) value as long as that value implements the
-interface's methods. A well-known pair of examples is
-io.Reader and io.Writer, the types
-Reader and Writer from the
-io package:
-
-Any type that implements a Read (or
-Write) method with this signature is said to implement
-io.Reader (or io.Writer). For the
-purposes of this discussion, that means that a variable of type
-io.Reader can hold any value whose type has a
-Read method:
-
-It's important to be clear that whatever concrete value
-r may hold, r's type is always
-io.Reader: Go is statically typed and the static type
-of r is io.Reader.
-An extremely important example of an interface type is the empty -interface: -
- -
-interface{}
-
-
--It represents the empty set of methods and is satisfied by any -value at all, since any value has zero or more methods. -
- --Some people say that Go's interfaces are dynamically typed, but -that is misleading. They are statically typed: a variable of -interface type always has the same static type, and even though at -run time the value stored in the interface variable may change -type, that value will always satisfy the interface. -
- --We need to be precise about all this because reflection and -interfaces are closely related. -
- -The representation of an interface
- --Russ Cox has written a -detailed blog post -about the representation of interface values in Go. It's not necessary to -repeat the full story here, but a simplified summary is in order. -
- --A variable of interface type stores a pair: the concrete value -assigned to the variable, and that value's type descriptor. -To be more precise, the value is the underlying concrete data item -that implements the interface and the type describes the full type -of that item. For instance, after -
- -{{code "/doc/progs/interface.go" `/func typeAssertions/` `/STOP/`}} - -
-r contains, schematically, the (value, type) pair,
-(tty, *os.File). Notice that the type
-*os.File implements methods other than
-Read; even though the interface value provides access
-only to the Read method, the value inside carries all
-the type information about that value. That's why we can do things
-like this:
-
-The expression in this assignment is a type assertion; what it
-asserts is that the item inside r also implements
-io.Writer, and so we can assign it to w.
-After the assignment, w will contain the pair
-(tty, *os.File). That's the same pair as
-was held in r. The static type of the interface
-determines what methods may be invoked with an interface variable,
-even though the concrete value inside may have a larger set of
-methods.
-
-Continuing, we can do this: -
- -{{code "/doc/progs/interface.go" `/var empty interface{}/` `/STOP/`}} - -
-and our empty interface value, empty, will again contain
-that same pair, (tty, *os.File). That's
-handy: an empty interface can hold any value and contains all the
-information we could ever need about that value.
-
-(We don't need a type assertion here because it's known statically
-that w satisfies the empty interface. In the example
-where we moved a value from a Reader to a
-Writer, we needed to be explicit and use a type
-assertion because Writer's methods are not a
-subset of Reader's.)
-
-One important detail is that the pair inside an interface always -has the form (value, concrete type) and cannot have the form -(value, interface type). Interfaces do not hold interface -values. -
- --Now we're ready to reflect. -
- -The first law of reflection
- -1. Reflection goes from interface value to reflection object.
- -
-At the basic level, reflection is just a mechanism to examine the
-type and value pair stored inside an interface variable. To get
-started, there are two types we need to know about in
-package reflect:
-Type and
-Value. Those two types
-give access to the contents of an interface variable, and two
-simple functions, called reflect.TypeOf and
-reflect.ValueOf, retrieve reflect.Type
-and reflect.Value pieces out of an interface value.
-(Also, from the reflect.Value it's easy to get
-to the reflect.Type, but let's keep the
-Value and Type concepts separate for
-now.)
-
-Let's start with TypeOf:
-
-This program prints -
- --type: float64 -- -
-You might be wondering where the interface is here, since the program looks
-like it's passing the float64 variable x, not an
-interface value, to reflect.TypeOf. But it's there; as
-godoc reports, the signature of
-reflect.TypeOf includes an empty interface:
-
-// TypeOf returns the reflection Type of the value in the interface{}.
-func TypeOf(i interface{}) Type
-
-
-
-When we call reflect.TypeOf(x), x is
-first stored in an empty interface, which is then passed as the
-argument; reflect.TypeOf unpacks that empty interface
-to recover the type information.
-
-The reflect.ValueOf function, of course, recovers the
-value (from here on we'll elide the boilerplate and focus just on
-the executable code):
-
-prints -
- --value: <float64 Value> -- -
-Both reflect.Type and reflect.Value have
-lots of methods to let us examine and manipulate them. One
-important example is that Value has a
-Type method that returns the Type of a
-reflect.Value. Another is that both Type
-and Value have a Kind method that returns
-a constant indicating what sort of item is stored:
-Uint, Float64, Slice, and so
-on. Also methods on Value with names like
-Int and Float let us grab values (as
-int64 and float64) stored inside:
-
-prints -
- --type: float64 -kind is float64: true -value: 3.4 -- -
-There are also methods like SetInt and
-SetFloat but to use them we need to understand
-settability, the subject of the third law of reflection, discussed
-below.
-
-The reflection library has a couple of properties worth singling
-out. First, to keep the API simple, the "getter" and "setter"
-methods of Value operate on the largest type that can
-hold the value: int64 for all the signed integers, for
-instance. That is, the Int method of
-Value returns an int64 and the
-SetInt value takes an int64; it may be
-necessary to convert to the actual type involved:
-
-The second property is that the Kind of a reflection
-object describes the underlying type, not the static type. If a
-reflection object contains a value of a user-defined integer type,
-as in
-
-the Kind of v is still
-reflect.Int, even though the static type of
-x is MyInt, not int. In
-other words, the Kind cannot discriminate an int from
-a MyInt even though the Type can.
-
The second law of reflection
- -2. Reflection goes from reflection object to interface -value.
- --Like physical reflection, reflection in Go generates its own -inverse. -
- -
-Given a reflect.Value we can recover an interface
-value using the Interface method; in effect the method
-packs the type and value information back into an interface
-representation and returns the result:
-
-// Interface returns v's value as an interface{}.
-func (v Value) Interface() interface{}
-
-
--As a consequence we can say -
- -{{code "/doc/progs/interface2.go" `/START f3b/` `/STOP/`}} - -
-to print the float64 value represented by the
-reflection object v.
-
-We can do even better, though. The arguments to
-fmt.Println, fmt.Printf and so on are all
-passed as empty interface values, which are then unpacked by the
-fmt package internally just as we have been doing in
-the previous examples. Therefore all it takes to print the contents
-of a reflect.Value correctly is to pass the result of
-the Interface method to the formatted print
-routine:
-
-(Why not fmt.Println(v)? Because v is a
-reflect.Value; we want the concrete value it holds.)
-Since our value is a float64, we can even use a
-floating-point format if we want:
-
-and get in this case -
- --3.4e+00 -- -
-Again, there's no need to type-assert the result of
-v.Interface() to float64; the empty
-interface value has the concrete value's type information inside
-and Printf will recover it.
-
-In short, the Interface method is the inverse of the
-ValueOf function, except that its result is always of
-static type interface{}.
-
-Reiterating: Reflection goes from interface values to reflection -objects and back again. -
- -The third law of reflection
- -3. To modify a reflection object, the value must be settable.
- --The third law is the most subtle and confusing, but it's easy -enough to understand if we start from first principles. -
- --Here is some code that does not work, but is worth studying. -
- -{{code "/doc/progs/interface2.go" `/START f4/` `/STOP/`}} - --If you run this code, it will panic with the cryptic message -
- --panic: reflect.Value.SetFloat using unaddressable value -- -
-The problem is not that the value 7.1 is not
-addressable; it's that v is not settable. Settability
-is a property of a reflection Value, and not all
-reflection Values have it.
-
-The CanSet method of Value reports the
-settability of a Value; in our case,
-
-prints -
- --settability of v: false -- -
-It is an error to call a Set method on an non-settable
-Value. But what is settability?
-
-Settability is a bit like addressability, but stricter. It's the -property that a reflection object can modify the actual storage -that was used to create the reflection object. Settability is -determined by whether the reflection object holds the original -item. When we say -
- -{{code "/doc/progs/interface2.go" `/START f6/` `/STOP/`}} - -
-we pass a copy of x to
-reflect.ValueOf, so the interface value created as the
-argument to reflect.ValueOf is a copy of
-x, not x itself. Thus, if the
-statement
-
-were allowed to succeed, it would not update x, even
-though v looks like it was created from
-x. Instead, it would update the copy of x
-stored inside the reflection value and x itself would
-be unaffected. That would be confusing and useless, so it is
-illegal, and settability is the property used to avoid this
-issue.
-
-If this seems bizarre, it's not. It's actually a familiar situation
-in unusual garb. Think of passing x to a
-function:
-
-f(x) -- -
-We would not expect f to be able to modify
-x because we passed a copy of x's value,
-not x itself. If we want f to modify
-x directly we must pass our function the address of
-x (that is, a pointer to x):
-f(&x)
-
-This is straightforward and familiar, and reflection works the same
-way. If we want to modify x by reflection, we must
-give the reflection library a pointer to the value we want to
-modify.
-
-Let's do that. First we initialize x as usual
-and then create a reflection value that points to it, called
-p.
-
-The output so far is -
- --type of p: *float64 -settability of p: false -- -
-The reflection object p isn't settable, but it's not
-p we want to set, it's (in effect) *p. To
-get to what p points to, we call the Elem
-method of Value, which indirects through the pointer,
-and save the result in a reflection Value called
-v:
-
-Now v is a settable reflection object, as the output
-demonstrates,
-
-settability of v: true -- -
-and since it represents x, we are finally able to use
-v.SetFloat to modify the value of
-x:
-
-The output, as expected, is -
- --7.1 -7.1 -- -
-Reflection can be hard to understand but it's doing exactly what
-the language does, albeit through reflection Types and
-Values that can disguise what's going on. Just keep in
-mind that reflection Values need the address of something in order
-to modify what they represent.
-
Structs
- -
-In our previous example v wasn't a pointer itself, it
-was just derived from one. A common way for this situation to arise
-is when using reflection to modify the fields of a structure. As
-long as we have the address of the structure, we can modify its
-fields.
-
-Here's a simple example that analyzes a struct value, t. We create
-the reflection object with the address of the struct because we'll want to
-modify it later. Then we set typeOfT to its type and iterate over
-the fields using straightforward method calls
-(see package reflect for details).
-Note that we extract the names of the fields from the struct type, but the
-fields themselves are regular reflect.Value objects.
-
-The output of this program is -
- --0: A int = 23 -1: B string = skidoo -- -
-There's one more point about settability introduced in
-passing here: the field names of T are upper case
-(exported) because only exported fields of a struct are
-settable.
-
-Because s contains a settable reflection object, we
-can modify the fields of the structure.
-
-And here's the result: -
- -
-t is now {77 Sunset Strip}
-
-
-
-If we modified the program so that s was created from
-t, not &t, the calls to
-SetInt and SetString would fail as the
-fields of t would not be settable.
-
Conclusion
- --Here again are the laws of reflection: -
- --Once you understand these laws reflection in Go becomes much easier -to use, although it remains subtle. It's a powerful tool that -should be used with care and avoided unless strictly -necessary. -
- --There's plenty more to reflection that we haven't covered — -sending and receiving on channels, allocating memory, using slices -and maps, calling methods and functions — but this post is -long enough. We'll cover some of those topics in a later -article. -
diff --git a/doc/articles/race_detector.html b/doc/articles/race_detector.html deleted file mode 100644 index 282db8ba40..0000000000 --- a/doc/articles/race_detector.html +++ /dev/null @@ -1,388 +0,0 @@ - - --Data races are among the most common and hardest to debug types of bugs in concurrent systems. -A data race occurs when two goroutines access the same variable concurrently and at least one of the accesses is a write. -See the The Go Memory Model for details. -
- --Here is an example of a data race that can lead to crashes and memory corruption: -
- -
-func main() {
- c := make(chan bool)
- m := make(map[string]string)
- go func() {
- m["1"] = "a" // First conflicting access.
- c <- true
- }()
- m["2"] = "b" // Second conflicting access.
- <-c
- for k, v := range m {
- fmt.Println(k, v)
- }
-}
-
-
-
-To help diagnose such bugs, Go includes a built-in data race detector.
-To use it, add the -race flag to the go command:
-
-$ go test -race mypkg // to test the package -$ go run -race mysrc.go // to run the source file -$ go build -race mycmd // to build the command -$ go install -race mypkg // to install the package -- -
-When the race detector finds a data race in the program, it prints a report. -The report contains stack traces for conflicting accesses, as well as stacks where the involved goroutines were created. -Here is an example: -
- --WARNING: DATA RACE -Read by goroutine 185: - net.(*pollServer).AddFD() - src/pkg/net/fd_unix.go:89 +0x398 - net.(*pollServer).WaitWrite() - src/pkg/net/fd_unix.go:247 +0x45 - net.(*netFD).Write() - src/pkg/net/fd_unix.go:540 +0x4d4 - net.(*conn).Write() - src/pkg/net/net.go:129 +0x101 - net.func·060() - src/pkg/net/timeout_test.go:603 +0xaf - -Previous write by goroutine 184: - net.setWriteDeadline() - src/pkg/net/sockopt_posix.go:135 +0xdf - net.setDeadline() - src/pkg/net/sockopt_posix.go:144 +0x9c - net.(*conn).SetDeadline() - src/pkg/net/net.go:161 +0xe3 - net.func·061() - src/pkg/net/timeout_test.go:616 +0x3ed - -Goroutine 185 (running) created at: - net.func·061() - src/pkg/net/timeout_test.go:609 +0x288 - -Goroutine 184 (running) created at: - net.TestProlongTimeout() - src/pkg/net/timeout_test.go:618 +0x298 - testing.tRunner() - src/pkg/testing/testing.go:301 +0xe8 -- -
-The GORACE environment variable sets race detector options.
-The format is:
-
-GORACE="option1=val1 option2=val2" -- -
-The options are: -
- -log_path (default stderr): The race detector writes
-its report to a file named log_path.pid.
-The special names stdout
-and stderr cause reports to be written to standard output and
-standard error, respectively.
-exitcode (default 66): The exit status to use when
-exiting after a detected race.
-strip_path_prefix (default ""): Strip this prefix
-from all reported file paths, to make reports more concise.
-history_size (default 1): The per-goroutine memory
-access history is 32K * 2**history_size elements.
-Increasing this value can avoid a "failed to restore the stack" error in reports, at the
-cost of increased memory usage.
-halt_on_error (default 0): Controls whether the program
-exits after reporting first data race.
--Example: -
- --$ GORACE="log_path=/tmp/race/report strip_path_prefix=/my/go/sources/" go test -race -- -
-When you build with -race flag, the go command defines additional
-build tag race.
-You can use the tag to exclude some code and tests when running the race detector.
-Some examples:
-
-// +build !race
-
-package foo
-
-// The test contains a data race. See issue 123.
-func TestFoo(t *testing.T) {
- // ...
-}
-
-// The test fails under the race detector due to timeouts.
-func TestBar(t *testing.T) {
- // ...
-}
-
-// The test takes too long under the race detector.
-func TestBaz(t *testing.T) {
- // ...
-}
-
-
-
-To start, run your tests using the race detector (go test -race).
-The race detector only finds races that happen at runtime, so it can't find
-races in code paths that are not executed.
-If your tests have incomplete coverage,
-you may find more races by running a binary built with -race under a realistic
-workload.
-
-Here are some typical data races. All of them can be detected with the race detector. -
- -
-func main() {
- var wg sync.WaitGroup
- wg.Add(5)
- for i := 0; i < 5; i++ {
- go func() {
- fmt.Println(i) // Not the 'i' you are looking for.
- wg.Done()
- }()
- }
- wg.Wait()
-}
-
-
-
-The variable i in the function literal is the same variable used by the loop, so
-the read in the goroutine races with the loop increment.
-(This program typically prints 55555, not 01234.)
-The program can be fixed by making a copy of the variable:
-
-func main() {
- var wg sync.WaitGroup
- wg.Add(5)
- for i := 0; i < 5; i++ {
- go func(j int) {
- fmt.Println(j) // Good. Read local copy of the loop counter.
- wg.Done()
- }(i)
- }
- wg.Wait()
-}
-
-
-
-// ParallelWrite writes data to file1 and file2, returns the errors.
-func ParallelWrite(data []byte) chan error {
- res := make(chan error, 2)
- f1, err := os.Create("file1")
- if err != nil {
- res <- err
- } else {
- go func() {
- // This err is shared with the main goroutine,
- // so the write races with the write below.
- _, err = f1.Write(data)
- res <- err
- f1.Close()
- }()
- }
- f2, err := os.Create("file2") // The second conflicting write to err.
- if err != nil {
- res <- err
- } else {
- go func() {
- _, err = f2.Write(data)
- res <- err
- f2.Close()
- }()
- }
- return res
-}
-
-
-
-The fix is to introduce new variables in the goroutines (note the use of :=):
-
- ... - _, err := f1.Write(data) - ... - _, err := f2.Write(data) - ... -- -
-If the following code is called from several goroutines, it leads to races on the service map.
-Concurrent reads and writes of the same map are not safe:
-
-var service map[string]net.Addr
-
-func RegisterService(name string, addr net.Addr) {
- service[name] = addr
-}
-
-func LookupService(name string) net.Addr {
- return service[name]
-}
-
-
--To make the code safe, protect the accesses with a mutex: -
- -
-var (
- service map[string]net.Addr
- serviceMu sync.Mutex
-)
-
-func RegisterService(name string, addr net.Addr) {
- serviceMu.Lock()
- defer serviceMu.Unlock()
- service[name] = addr
-}
-
-func LookupService(name string) net.Addr {
- serviceMu.Lock()
- defer serviceMu.Unlock()
- return service[name]
-}
-
-
-
-Data races can happen on variables of primitive types as well (bool, int, int64, etc.),
-as in this example:
-
-type Watchdog struct{ last int64 }
-
-func (w *Watchdog) KeepAlive() {
- w.last = time.Now().UnixNano() // First conflicting access.
-}
-
-func (w *Watchdog) Start() {
- go func() {
- for {
- time.Sleep(time.Second)
- // Second conflicting access.
- if w.last < time.Now().Add(-10*time.Second).UnixNano() {
- fmt.Println("No keepalives for 10 seconds. Dying.")
- os.Exit(1)
- }
- }
- }()
-}
-
-
--Even such "innocent" data races can lead to hard-to-debug problems caused by -non-atomicity of the memory accesses, -interference with compiler optimizations, -or reordering issues accessing processor memory . -
- -
-A typical fix for this race is to use a channel or a mutex.
-To preserve the lock-free behavior, one can also use the
-sync/atomic package.
-
-type Watchdog struct{ last int64 }
-
-func (w *Watchdog) KeepAlive() {
- atomic.StoreInt64(&w.last, time.Now().UnixNano())
-}
-
-func (w *Watchdog) Start() {
- go func() {
- for {
- time.Sleep(time.Second)
- if atomic.LoadInt64(&w.last) < time.Now().Add(-10*time.Second).UnixNano() {
- fmt.Println("No keepalives for 10 seconds. Dying.")
- os.Exit(1)
- }
- }
- }()
-}
-
-
-
-The race detector runs on darwin/amd64, linux/amd64, and windows/amd64.
-
-The cost of race detection varies by program, but for a typical program, memory -usage may increase by 5-10x and execution time by 2-20x. -
diff --git a/doc/articles/slice-1.png b/doc/articles/slice-1.png deleted file mode 100644 index ba465cf718..0000000000 Binary files a/doc/articles/slice-1.png and /dev/null differ diff --git a/doc/articles/slice-2.png b/doc/articles/slice-2.png deleted file mode 100644 index a57581e8cf..0000000000 Binary files a/doc/articles/slice-2.png and /dev/null differ diff --git a/doc/articles/slice-3.png b/doc/articles/slice-3.png deleted file mode 100644 index 64ece5e877..0000000000 Binary files a/doc/articles/slice-3.png and /dev/null differ diff --git a/doc/articles/slice-array.png b/doc/articles/slice-array.png deleted file mode 100644 index a533702cf6..0000000000 Binary files a/doc/articles/slice-array.png and /dev/null differ diff --git a/doc/articles/slice-struct.png b/doc/articles/slice-struct.png deleted file mode 100644 index f9141fc592..0000000000 Binary files a/doc/articles/slice-struct.png and /dev/null differ diff --git a/doc/articles/slices_usage_and_internals.html b/doc/articles/slices_usage_and_internals.html deleted file mode 100644 index ebdca01503..0000000000 --- a/doc/articles/slices_usage_and_internals.html +++ /dev/null @@ -1,438 +0,0 @@ - - --Go's slice type provides a convenient and efficient means of working with -sequences of typed data. Slices are analogous to arrays in other languages, but -have some unusual properties. This article will look at what slices are and how -they are used. -
- --Arrays -
- --The slice type is an abstraction built on top of Go's array type, and so to -understand slices we must first understand arrays. -
- -
-An array type definition specifies a length and an element type. For example,
-the type [4]int represents an array of four integers. An array's
-size is fixed; its length is part of its type ([4]int and
-[5]int are distinct, incompatible types). Arrays can be indexed in
-the usual way, so the expression s[n] accesses the nth
-element, starting from zero.
-
-var a [4]int -a[0] = 1 -i := a[0] -// i == 1 -- -
-Arrays do not need to be initialized explicitly; the zero value of an array is -a ready-to-use array whose elements are themselves zeroed: -
- --// a[2] == 0, the zero value of the int type -- -
-The in-memory representation of [4]int is just four integer values laid out sequentially:
-
- -
-
-Go's arrays are values. An array variable denotes the entire array; it is not a -pointer to the first array element (as would be the case in C). This means -that when you assign or pass around an array value you will make a copy of its -contents. (To avoid the copy you could pass a pointer to the array, but -then that's a pointer to an array, not an array.) One way to think about arrays -is as a sort of struct but with indexed rather than named fields: a fixed-size -composite value. -
- --An array literal can be specified like so: -
- -
-b := [2]string{"Penn", "Teller"}
-
-
--Or, you can have the compiler count the array elements for you: -
- -
-b := [...]string{"Penn", "Teller"}
-
-
-
-In both cases, the type of b is [2]string.
-
-Slices -
- --Arrays have their place, but they're a bit inflexible, so you don't see them -too often in Go code. Slices, though, are everywhere. They build on arrays to -provide great power and convenience. -
- -
-The type specification for a slice is []T, where T is
-the type of the elements of the slice. Unlike an array type, a slice type has
-no specified length.
-
-A slice literal is declared just like an array literal, except you leave out -the element count: -
- -
-letters := []string{"a", "b", "c", "d"}
-
-
-
-A slice can be created with the built-in function called make,
-which has the signature,
-
-func make([]T, len, cap) []T -- -
-where T stands for the element type of the slice to be created. The
-make function takes a type, a length, and an optional capacity.
-When called, make allocates an array and returns a slice that
-refers to that array.
-
-var s []byte
-s = make([]byte, 5, 5)
-// s == []byte{0, 0, 0, 0, 0}
-
-
--When the capacity argument is omitted, it defaults to the specified length. -Here's a more succinct version of the same code: -
- --s := make([]byte, 5) -- -
-The length and capacity of a slice can be inspected using the built-in
-len and cap functions.
-
-len(s) == 5 -cap(s) == 5 -- -
-The next two sections discuss the relationship between length and capacity. -
- -
-The zero value of a slice is nil. The len and
-cap functions will both return 0 for a nil slice.
-
-A slice can also be formed by "slicing" an existing slice or array. Slicing is
-done by specifying a half-open range with two indices separated by a colon. For
-example, the expression b[1:4] creates a slice including elements
-1 through 3 of b (the indices of the resulting slice will be 0
-through 2).
-
-b := []byte{'g', 'o', 'l', 'a', 'n', 'g'}
-// b[1:4] == []byte{'o', 'l', 'a'}, sharing the same storage as b
-
-
--The start and end indices of a slice expression are optional; they default to zero and the slice's length respectively: -
- -
-// b[:2] == []byte{'g', 'o'}
-// b[2:] == []byte{'l', 'a', 'n', 'g'}
-// b[:] == b
-
-
--This is also the syntax to create a slice given an array: -
- -
-x := [3]string{"Лайка", "Белка", "Стрелка"}
-s := x[:] // a slice referencing the storage of x
-
-
--Slice internals -
- --A slice is a descriptor of an array segment. It consists of a pointer to the -array, the length of the segment, and its capacity (the maximum length of the -segment). -
- -
- -
-
-Our variable s, created earlier by make([]byte, 5),
-is structured like this:
-
- -
-
-The length is the number of elements referred to by the slice. The capacity is -the number of elements in the underlying array (beginning at the element -referred to by the slice pointer). The distinction between length and capacity -will be made clear as we walk through the next few examples. -
- -
-As we slice s, observe the changes in the slice data structure and
-their relation to the underlying array:
-
-s = s[2:4] -- -
- -
-
-Slicing does not copy the slice's data. It creates a new slice value that -points to the original array. This makes slice operations as efficient as -manipulating array indices. Therefore, modifying the elements (not the -slice itself) of a re-slice modifies the elements of the original slice: -
- -
-d := []byte{'r', 'o', 'a', 'd'}
-e := d[2:]
-// e == []byte{'a', 'd'}
-e[1] = 'm'
-// e == []byte{'a', 'm'}
-// d == []byte{'r', 'o', 'a', 'm'}
-
-
-
-Earlier we sliced s to a length shorter than its capacity. We can
-grow s to its capacity by slicing it again:
-
-s = s[:cap(s)] -- -
- -
-
-A slice cannot be grown beyond its capacity. Attempting to do so will cause a -runtime panic, just as when indexing outside the bounds of a slice or array. -Similarly, slices cannot be re-sliced below zero to access earlier elements in -the array. -
- --Growing slices (the copy and append functions) -
- -
-To increase the capacity of a slice one must create a new, larger slice and
-copy the contents of the original slice into it. This technique is how dynamic
-array implementations from other languages work behind the scenes. The next
-example doubles the capacity of s by making a new slice,
-t, copying the contents of s into t, and
-then assigning the slice value t to s:
-
-t := make([]byte, len(s), (cap(s)+1)*2) // +1 in case cap(s) == 0
-for i := range s {
- t[i] = s[i]
-}
-s = t
-
-
--The looping piece of this common operation is made easier by the built-in copy -function. As the name suggests, copy copies data from a source slice to a -destination slice. It returns the number of elements copied. -
- --func copy(dst, src []T) int -- -
-The copy function supports copying between slices of different
-lengths (it will copy only up to the smaller number of elements). In addition,
-copy can handle source and destination slices that share the same
-underlying array, handling overlapping slices correctly.
-
-Using copy, we can simplify the code snippet above:
-
-t := make([]byte, len(s), (cap(s)+1)*2) -copy(t, s) -s = t -- -
-A common operation is to append data to the end of a slice. This function -appends byte elements to a slice of bytes, growing the slice if necessary, and -returns the updated slice value: -
- -{{code "/doc/progs/slices.go" `/AppendByte/` `/STOP/`}} - -
-One could use AppendByte like this:
-
-p := []byte{2, 3, 5}
-p = AppendByte(p, 7, 11, 13)
-// p == []byte{2, 3, 5, 7, 11, 13}
-
-
-
-Functions like AppendByte are useful because they offer complete
-control over the way the slice is grown. Depending on the characteristics of
-the program, it may be desirable to allocate in smaller or larger chunks, or to
-put a ceiling on the size of a reallocation.
-
-But most programs don't need complete control, so Go provides a built-in
-append function that's good for most purposes; it has the
-signature
-
-func append(s []T, x ...T) []T -- -
-The append function appends the elements x to the end
-of the slice s, and grows the slice if a greater capacity is
-needed.
-
-a := make([]int, 1)
-// a == []int{0}
-a = append(a, 1, 2, 3)
-// a == []int{0, 1, 2, 3}
-
-
-
-To append one slice to another, use ... to expand the second
-argument to a list of arguments.
-
-a := []string{"John", "Paul"}
-b := []string{"George", "Ringo", "Pete"}
-a = append(a, b...) // equivalent to "append(a, b[0], b[1], b[2])"
-// a == []string{"John", "Paul", "George", "Ringo", "Pete"}
-
-
-
-Since the zero value of a slice (nil) acts like a zero-length
-slice, you can declare a slice variable and then append to it in a loop:
-
-A possible "gotcha" -
- --As mentioned earlier, re-slicing a slice doesn't make a copy of the underlying -array. The full array will be kept in memory until it is no longer referenced. -Occasionally this can cause the program to hold all the data in memory when -only a small piece of it is needed. -
- -
-For example, this FindDigits function loads a file into memory and
-searches it for the first group of consecutive numeric digits, returning them
-as a new slice.
-
-This code behaves as advertised, but the returned []byte points
-into an array containing the entire file. Since the slice references the
-original array, as long as the slice is kept around the garbage collector can't
-release the array; the few useful bytes of the file keep the entire contents in
-memory.
-
-To fix this problem one can copy the interesting data to a new slice before -returning it: -
- -{{code "/doc/progs/slices.go" `/CopyDigits/` `/STOP/`}} - -
-A more concise version of this function could be constructed by using
-append. This is left as an exercise for the reader.
-
-Further Reading -
- --Effective Go contains an -in-depth treatment of slices -and arrays, -and the Go language specification -defines slices and their -associated -helper -functions. -
diff --git a/doc/cmd.html b/doc/cmd.html index ac54923d43..b8bdcdadec 100644 --- a/doc/cmd.html +++ b/doc/cmd.html @@ -27,9 +27,9 @@ the gotool subcommand.
-Finally, two of the commands, fmt and doc, are also
-installed as regular binaries called gofmt and godoc
-because they are so often referenced.
+Finally the fmt and godoc commands are installed
+as regular binaries called gofmt and godoc because
+they are so often referenced.
@@ -61,6 +61,13 @@ details.
"go test -coverprofile".
+A summary of the changes between Go releases.
+ ++A guide for updating your code to work with Go 1. +
+ ++A list of significant changes in Go 1.1, with instructions for updating your +code where necessary. +
+ ++A list of significant changes in Go 1.2, with instructions for updating your +code where necessary. +
+ ++What Go 1 defines and the backwards-compatibility guarantees one can expect as +Go 1 matures. +
+ +Check out the Go source code.
-A summary of the changes between Go releases.
-The golang-dev mailing list is for discussing and reviewing code for the Go project.
@@ -80,29 +107,3 @@ open issues that interest you. Those labeled HelpWanted are particularly in need of outside help. - - -The golang-nuts -mailing list is for general Go discussion.
- -A list of external Go projects including programs and libraries.
- -#go-nuts on irc.freenode.net is the official Go IRC channel.
- -The Google+ community for Go enthusiasts.
- -The Go project's Google+ page.
- -The Go project's official Twitter account.
- -The official blog of the Go project, featuring news and in-depth articles by -the Go team and guests.
diff --git a/doc/docs.html b/doc/docs.html index 32ce1d63bc..7aad8dadf4 100644 --- a/doc/docs.html +++ b/doc/docs.html @@ -58,49 +58,47 @@ A must read for any new Go programmer. It augments the tour and the language specification, both of which should be read first. -Language specification, memory model, and detailed documentation for the commands and packages.
- --How to develop and deploy a simple Go project with -Google App Engine. -
- -Answers to common questions about Go.
-A wiki maintained by the Go community.
--A guide for updating your code to work with Go 1. +See the Learn page at the Wiki +for more Go learning resources.
--A list of significant changes in Go 1.1, with instructions for updating your -code where necessary. +The documentation for the Go standard library.
--A list of significant changes in Go 1.2, with instructions for updating your -code where necessary. +The documentation for the Go tools.
--What Go 1 defines and the backwards-compatibility guarantees one can expect as -Go 1 matures. +The official Go Language specification.
-+A document that specifies the conditions under which reads of a variable in +one goroutine can be guaranteed to observe values produced by writes to the +same variable in a different goroutine. +
+ + +The official blog of the Go project, featuring news and in-depth articles by @@ -119,44 +117,46 @@ Guided tours of Go programs.
+See the Articles page at the +Wiki for more Go articles. +
+ + -
--The talks marked with a red asterisk (*) were written -before Go 1 and contain some examples that are no longer correct, but they are -still of value. -
-Three things that make Go fast, fun, and productive: @@ -164,63 +164,31 @@ interfaces, reflection, and concurrency. Builds a toy web crawler to demonstrate these.
++One of Go's key design goals is code adaptability; that it should be easy to take a simple design and build upon it in a clean and natural way. In this talk Andrew Gerrand describes a simple "chat roulette" server that matches pairs of incoming TCP connections, and then use Go's concurrency mechanisms, interfaces, and standard library to extend it with a web interface and other features. While the function of the program changes dramatically, Go's flexibility preserves the original design as it grows. +
+Concurrency is the key to designing high performance network services. Go's concurrency primitives (goroutines and channels) provide a simple and efficient means of expressing concurrent execution. In this talk we see how tricky concurrency problems can be solved gracefully with simple Go code.
--A panel discussion with David Symonds, Robert Griesemer, Rob Pike, Ken Thompson, Andrew Gerrand, and Brad Fitzpatrick. -
- --A talk by Rob Pike and Andrew Gerrand presented at Google I/O 2011. -It walks through the construction and deployment of a simple web application -and unveils the Go runtime for App Engine. -See the presentation slides. -
- --A presentation delivered by Rob Pike and Russ Cox at Google I/O 2010. It -illustrates how programming in Go differs from other languages through a set of -examples demonstrating features particular to Go. These include concurrency, -embedded types, methods on any type, and program construction using interfaces. +This talk expands on the Go Concurrency Patterns talk to dive deeper into Go's concurrency primitives.
-See the GoTalks -page at the Go Wiki for -more Go talks. +See the Go Talks site and wiki page for more Go talks.
+-See the NonEnglish page -at the Go Wiki for localized +See the NonEnglish page +at the Wiki for localized documentation.
- - -
-
-
-The golang-nuts -mailing list is for general Go discussion.
- -A list of external Go projects including programs and libraries.
- -#go-nuts on irc.freenode.net is the official Go IRC channel.
- -The Go project's Google+ page.
- -The Go project's official Twitter account.
diff --git a/doc/go1.html b/doc/go1.html index 2687827c0e..3bbe5d3168 100644 --- a/doc/go1.html +++ b/doc/go1.html @@ -1,5 +1,6 @@ diff --git a/doc/go1compat.html b/doc/go1compat.html index 1dfd382c23..7ca3d355d6 100644 --- a/doc/go1compat.html +++ b/doc/go1compat.html @@ -1,5 +1,6 @@